树和二叉树
树的性质
- 结点数 = 总度数 + 1
- 对于一颗二叉树,其总结点数为 , 度为 0 的结点个数为 ,度为 1 的结点个数为 ,度为 2 的结点个数为 ,则有:
结点总数=度为 0 的个数+度为 1 的个数+度为 2 的个数,即:- 设 为分支总数,因为除了根结点以外所有结点都有且仅有一个直接前驱,所以 ,又因为这些分支由度为 1 或 2 的结点射出,则有 ,所以, ,可得
- 度为 的数和 叉树的区别
- 度为 的树: 至少有一个结点的度 =
- 叉树: 允许所有节点的度 <
- 度为 的树: 一定是非空树,至少有 个结点
- 叉树:可以是空树
- 度为 的树第 层最多有 个结点(), 叉树同理
- 高度为 的 叉树最多有 个结点(高度为的二叉树最多有个结点)
- 高度为 的 叉树至少有 个结点
- 高度为 、度为 的树至少有 个结点
- 具有 个结点的 叉树的最小高度为
树的存储结构
双亲表示法(顺序存储)
顺序存储结点数据, 结点中保存父节点在数组中的下标
优点:找父节点方便;缺点:找孩子不方便


上面的树用实际代码(Java)可表示为:
public class ParentTree {
PTNode nodes[]; // 双亲表示
int n; // 结点数
public static void main(String[] args) {
ParentTree parentTree = new ParentTree();
parentTree.nodes = new PTNode[100];
// 根节点固定存储在0, -1表示没有双亲
parentTree.nodes[0] = new PTNode("A", -1);
parentTree.nodes[1] = new PTNode("B", 0);
parentTree.nodes[2] = new PTNode("C", 0);
parentTree.nodes[3] = new PTNode("D", 0);
parentTree.nodes[4] = new PTNode("E", 1);
parentTree.nodes[5] = new PTNode("F", 1);
parentTree.nodes[6] = new PTNode("G", 2);
parentTree.nodes[7] = new PTNode("H", 3);
parentTree.nodes[8] = new PTNode("I", 3);
parentTree.nodes[9] = new PTNode("J", 3);
parentTree.nodes[10] = new PTNode("K", 4);
}
}
class PTNode<elemType> {
elemType data; // 数据元素
int parent; // 双亲位置域
public PTNode(elemType data, int parent) {
this.data = data;
this.parent = parent;
}
}
孩子表示法(顺序+链式存储)
顺序存储各个节点,每个节点中保存孩子链表头指针

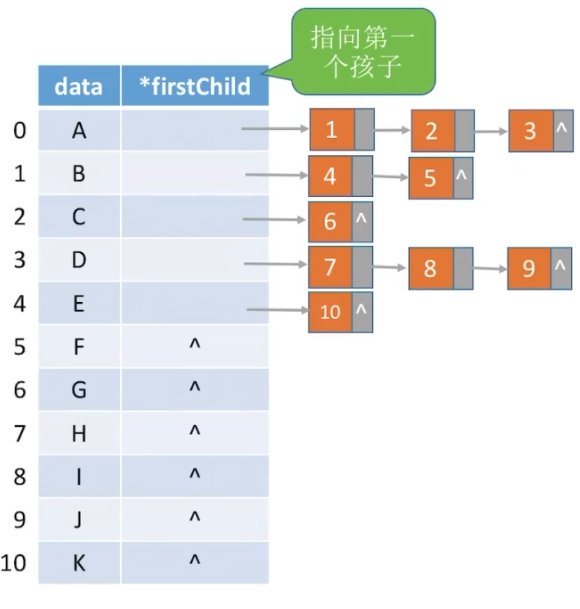
孩子兄弟表示法(链式存储)
 =>
=> 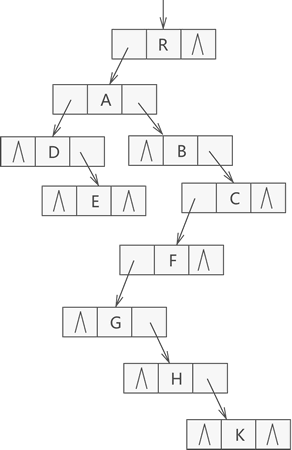
- 用二叉链表存储树-左孩子右兄弟
- 孩子兄弟表示法存储的树, 从存储视角来看形态上和二叉树类似
森林与二叉树的转换
- 本质就是用二叉链表存储森林-左孩子右兄弟
- 森林中各个树的根结点之间视为兄弟关系
二叉树(Binary tree)
1. 二叉树的概念
- 可为空二叉树
- 任意结点的度≤2
- 是有序树,左子树、右子树不可颠倒
2. 特殊二叉树
2.1 满二叉树
高度为,含有个结点的二叉树
特点:
- 只有最后一层有叶子结点
- 不存在度为 1 的结点
- 按层序从 1 开始编号,结点i的左孩子为,右孩子为;结点i的父节点为(如果有的话)

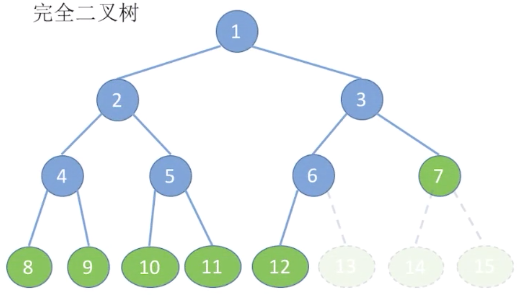
2.2 完全二叉树
当且仅当其每个结点都与高度为的满二叉树中编号的结点一一对应时,称为完全二叉树。
在满二叉树的基础上可去掉若干个编号更大的结点。
特点:
- 只有最后两层可能有叶子结点
- 最多只有一个度为 1 的结点
- 按层序从 1 开始编号,结点i的左孩子为,右孩子为;结点i的父节点为(如果有的话)
2.3 二叉排序树
左子树关键字 < 根节点关键字 < 右子树关键字,具备此性质的二叉树则称为二叉排序树
2.4 平衡二叉树
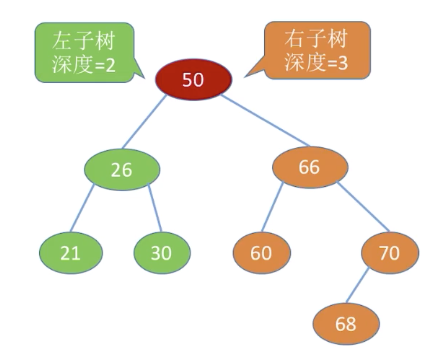
树上任一结点的左右子树深度差不超过1
3. 二叉树的性质
-
设非空二叉树中度为0、1和2的结点个数分别为,则(叶子结点比二分支结点多一个)。假设树中结点总数为,则:
-
二叉树第 层至多有个结点(i ≥ 1)
- 叉树第 层至多有个结点(i ≥ 1)
- 叉树第 层至多有个结点(i ≥ 1)
-
高度为 的二叉树至多有 个结点(满二叉树)
- 高度为 的 叉树至多有 个结点
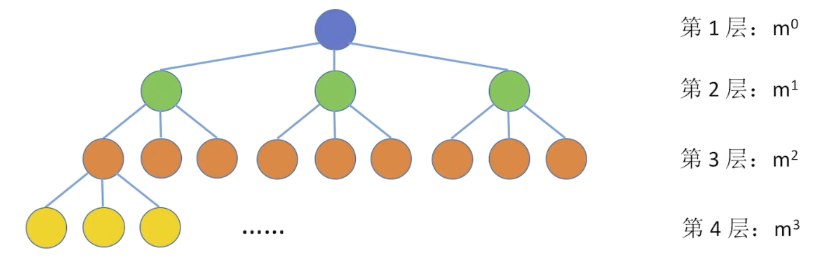
- 高度为 的 叉树至多有 个结点
4. 完全二叉树的性质
- 具有个 结点的完全二叉树的高度为
- 高为的满二叉树共有个结点
- 高为的完全二叉树至少 个结点至多 个结点
- 高为的满二叉树共有个结点
- 对于完全二叉树,可以由的结点数推出度为0、1和2的结点个数为
完全二叉树最多只有一个度为1的结点,即
=> 一定是奇数
若完全二叉树有个(偶数)个结点,则必有
若完全二叉树有个(奇数)个结点,则必有
5. 二叉树的存储结构
5.1 二叉树的顺序存储
在二叉树的顺序存储中,一定要把二叉树的结点编号与完全二叉树对应起来
- 的左孩子 —
- 的右孩子 —
- 的父节点 —
最坏情况:高度为且只有个结点的单支树(所有结点只有右孩子),也至少需要个存储单元。所以,二叉树的顺序存储结构只适合存储完全二叉树
public class SeqStorageBinaryTree {
static int maxSize = 100;
static TreeNode[] t = new TreeNode[maxSize];
public static void main(String[] args) {
for (int i = 1; i < t.length; i++) {
t[i] = new TreeNode(i);
}
}
}
class TreeNode {
/**
* 结点中的数据元素
*/
int value;
/**
* 结点是否为空
*/
boolean isEmpty;
public TreeNode(int value) {
this.value = value;
// 初始化结点为空
this.isEmpty = false;
}
}
5.2 二叉树的链式存储
个结点的二叉链表共有个空链域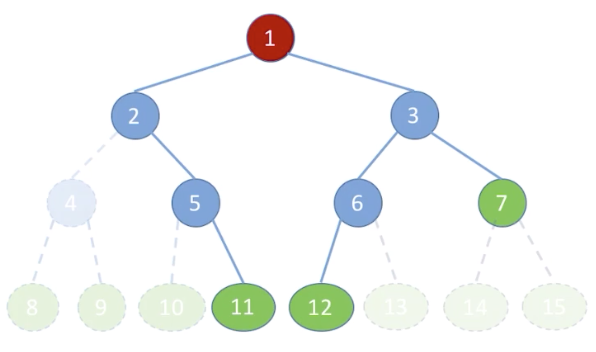
public class LinkedStorageBinaryTree {
public static void main(String[] args) {
// 构建上图的二叉树, 后面遍历的代码实现都是基于此树.
TreeNodeLinked root = new TreeNodeLinked(1);
TreeNodeLinked node1 = new TreeNodeLinked(2);
TreeNodeLinked node1 = new TreeNodeLinked(2);
TreeNodeLinked node2 = new TreeNodeLinked(3);
TreeNodeLinked node3 = new TreeNodeLinked(5);
TreeNodeLinked node4 = new TreeNodeLinked(6);
TreeNodeLinked node5 = new TreeNodeLinked(7);
TreeNodeLinked node6 = new TreeNodeLinked(11);
TreeNodeLinked node7 = new TreeNodeLinked(12);
root.lChild = node1; root.rChild = node2;
node1.lChild = node3;
node2.lChild = node4; node2.rChild = node5;
node3.rChild = node6;
node4.lChild = node7;
}
}
class TreeNodeLinked {
int value; // 数据域
TreeNodeLinked lChild, rChild; // 左、右孩子
public TreeNodeLinked(int value) {
this.value = value;
this.lChild = null;
this.rChild = null;
}
}
6. 二叉树的遍历
6.1 先序遍历(根、左、右)
public static void preOrder(TreeNodeLinked tNode) {
if(tNode != null) {
// 访问根结点
System.out.print(tNode.value + "");
// 递归遍历左子树
preOrder(tNode.lChild);
// 递归遍历右子树
preOrder(tNode.rChild);
}
}
6.2 中序遍历(左、根、右)
public static void midOrder(TreeNodeLinked tNode) {
if(tNode != null) {
// 递归遍历左子树
preOrder(tNode.lChild);
// 访问根结点
System.out.print(tNode.value + " ");
// 递归遍历右子树
preOrder(tNode.rChild);
}
}
6.3 后序遍历(左、右、根)
public static void postOrder(TreeNodeLinked tNode) {
if(tNode != null) {
// 递归遍历左子树
preOrder(tNode.lChild);
// 递归遍历右子树
preOrder(tNode.rChild);
// 访问根结点
System.out.print(tNode.value + " ");
}
}
6.4 求树的深度(后序遍历算法的变种)
public static int treeDepth(TreeNodeLinked t) {
if (t == null) {
return 0;
}
int l = treeDepth(t.lChild);
int r = treeDepth(t.rChild);
// 树的深度 = max(左子树深度, 右子树深度) + 1
return Math.max(l, r) + 1;
}
6.5 层序遍历(BFS)
算法思想:
- 初始化一个辅助队列
- 根节点入队
- 若队列非空,则队头结点出队,访问该结点,并将其左、右孩子插入队尾(如果有的话)
- 重复3直至队列为空
public static void levelOrder(TreeNodeLinked t) {
// 初始化一个辅助队列
Queue<TreeNodeLinked> queue = new ArrayBlockingQueue<>(50);
// 根结点入队
queue.add(t);
while(!queue.isEmpty()) {
// 队头结点出队
TreeNodeLinked poll = queue.poll();
System.out.print(poll.value + " ");
// 将左右孩子插入队尾
if(poll.lChild != null) {
queue.add(poll.lChild);
}
if(poll.rChild != null) {
queue.add(poll.rChild);
}
}
}
线索二叉树(Threaded Binary Tree)
二叉树添加了直接指向节点的前驱和后继的指针的二叉树称为线索二叉树(Threaded binary tree)
作用
方便从一个指定结点出发,找到其前驱、后继;方便遍历
存储结构
- 在普通二叉树结点的基础上,增加两个标志位
lTag和rTag lTag == 1时,表示lChild指向前驱;lTag == 0时,表示lChild指向左孩子rTag == 1时,表示rChild指向后继;rTag == 0时,表示lChild指向右孩子
public class ThreadNode {
/**
* 数据域
*/
private int data;
/**
* 左右孩子
*/
private ThreadNode lChild, rChild;
/**
* 左右线索标志, 1为前驱后继, 0为左右孩子
*/
private int lTag, rTag;
public ThreadNode(int data) {
this.data = data;
this.lTag = 0; this.rTag = 0;
}
/* get and set... */
}
线索化二叉树
中序线索化二叉树
/**
* 中序线索化二叉树
* @param node 二叉树的根节点
*/
public void threadedNodes(ThreadNode node) {
if (node == null) {
return;
}
// 处理当前结点的前驱结点
threadedNodes(node.getlChild());
if (node.getlChild() == null) {
node.setlChild(pre);
node.setlTag(1);
}
// 处理当前结点的后继结点
if (pre != null && pre.getrChild() == null) {
pre.setrChild(node);
pre.setrTag(1);
}
// 每处理完一个结点后, 让当前结点是下一个结点的前驱结点
pre = node;
threadedNodes(node.getrChild());
}
遍历线索二叉树
遍历中序线索二叉树
/**
* 遍历中序线索二叉树
* @param node 根节点
*/
public void threadedNodesList(ThreadNode node) {
ThreadNode current = node;
while(current != null) {
while(current.getlTag() == 0) {
current = current.getlChild();
}
System.out.println(current.getData());
// 如果当前结点的右指针指向的是后继结点, 则一直访问
while(current.getrTag() == 1) {
current = current.getrChild();
System.out.println(current.getData());
}
current = current.getrChild();
}
}
堆(Heap)
堆的概念
- 堆(Heap)是一种特别的完全二叉树。
- 堆分为两种: 最大堆(大根堆)和最小堆(小跟堆), 大顶堆在堆排序中用于升序排序,而小顶堆则是降序排序
- 在最大堆中, 父节点的值比每一个子结点的值都要大。在最小堆中,父节点的值比每一个子结点都要小。这就是所谓的“堆属性”, 并且这个属性对堆中的每一个节点都成立.
堆节点的访问
数组起始位置为0情况下:
- 父节点的左子节点在位置
- 父节点的右子节点在位置
- 子节点的父节点在位置
堆排序(Heap Sort)
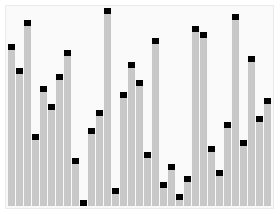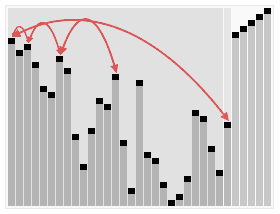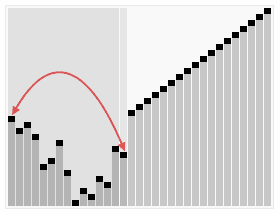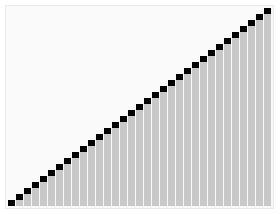
最优/最坏时间复杂度:
算法思路

1.调整成堆
将待排序序列构造成一个最大堆/最小堆
b. 此时我们从最后一个非叶子节点(arr.length/2-1或(i-1)/2 => (arr.length-1-1)/2)开始, 从左至右, 从下至上进行调整
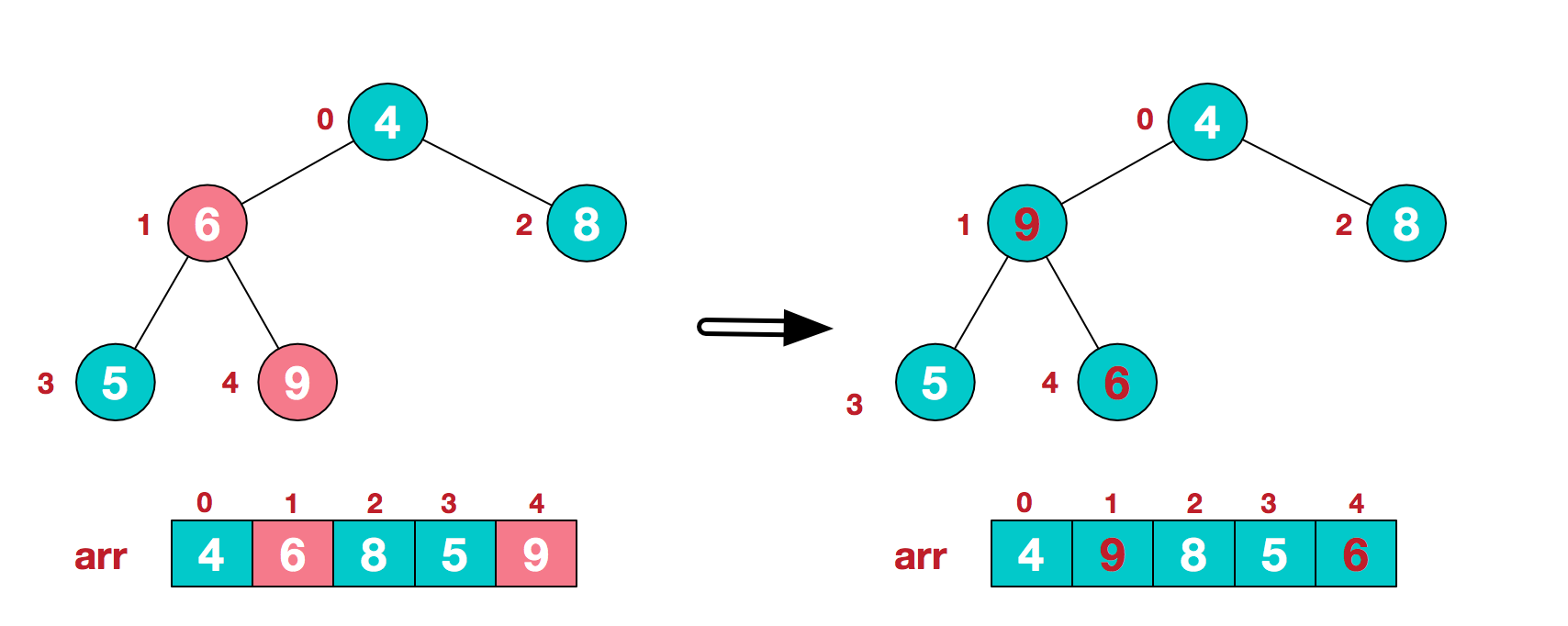
c. 找到第二个非叶子节点4, 由于[4,9,8]中9元素最大, 4和9交换
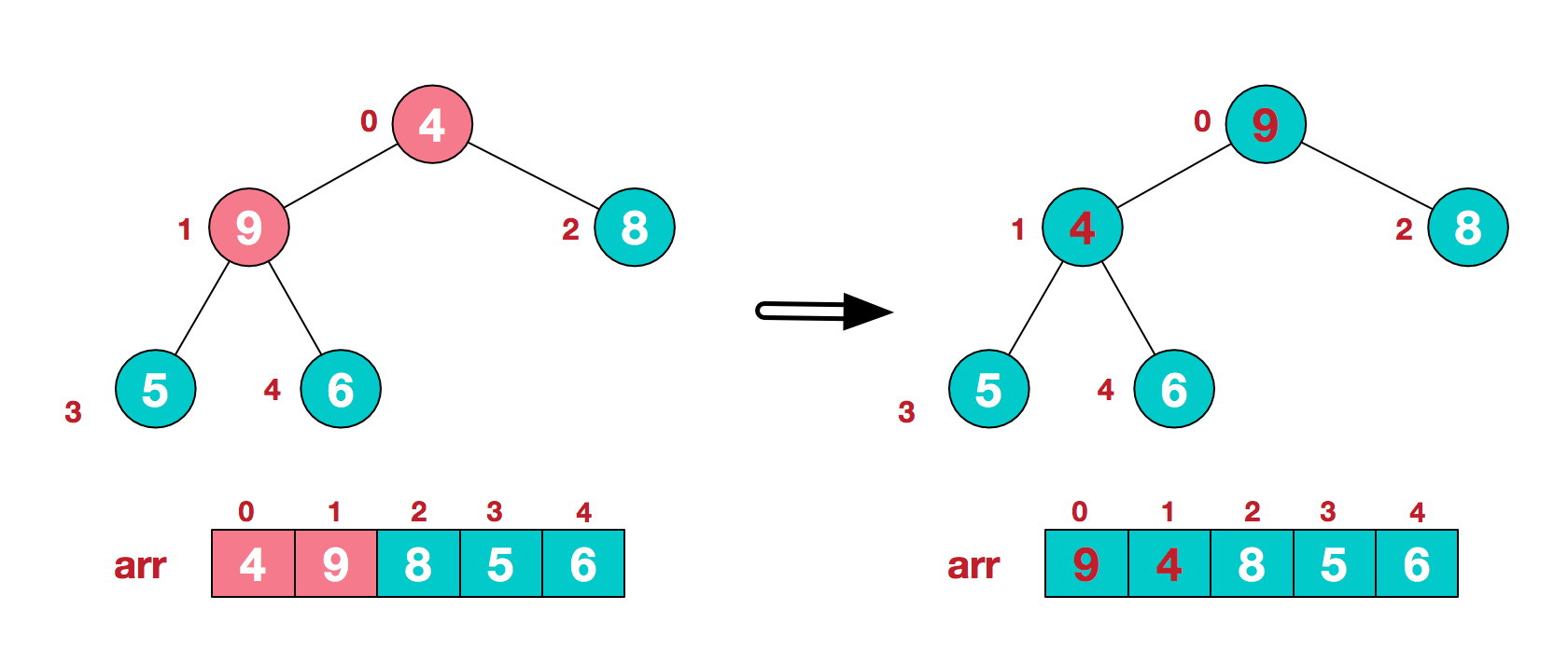
d. 这时交换导致了子根节点[4,5,6]结构混乱, 继续调整, 将4和6交换
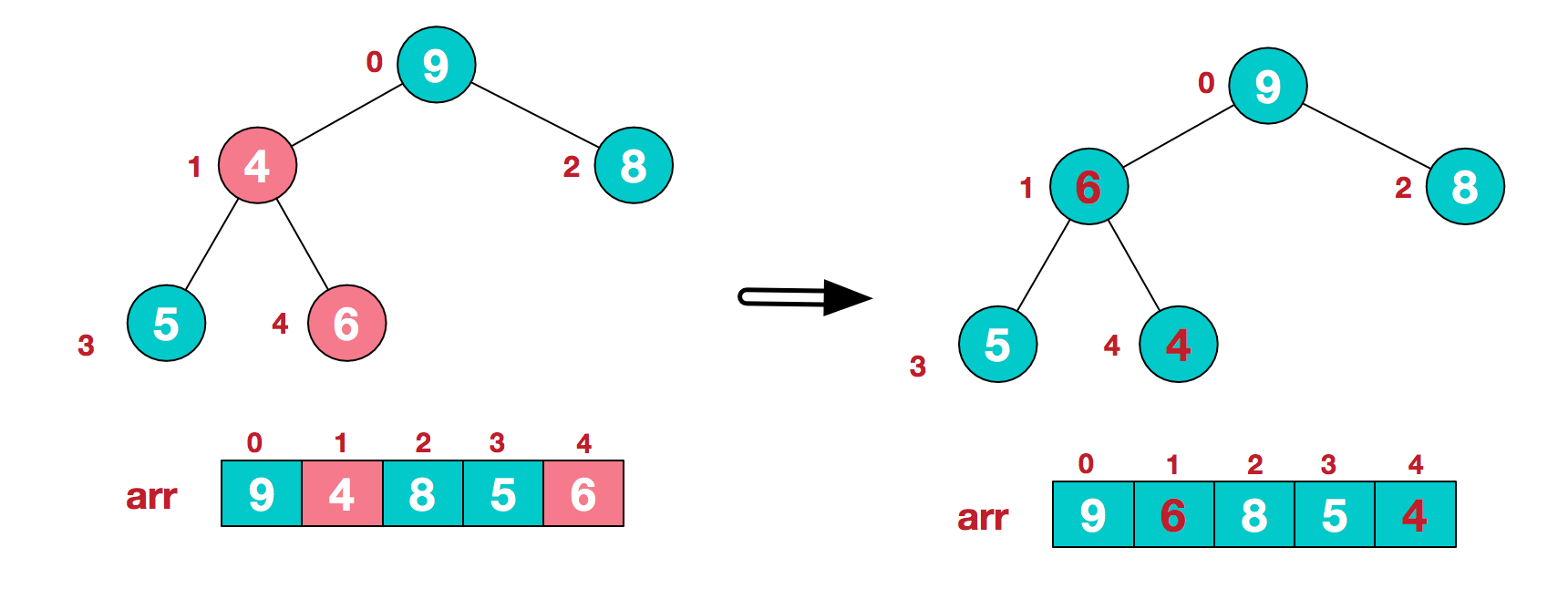
此时, 就已经将一个无序序列构造成一个大顶堆了
2.交换元素
将堆顶元素与末尾元素交换, 使得最大/最小元素在数组末端
e. 将堆顶元素9和末尾元素4进行交换
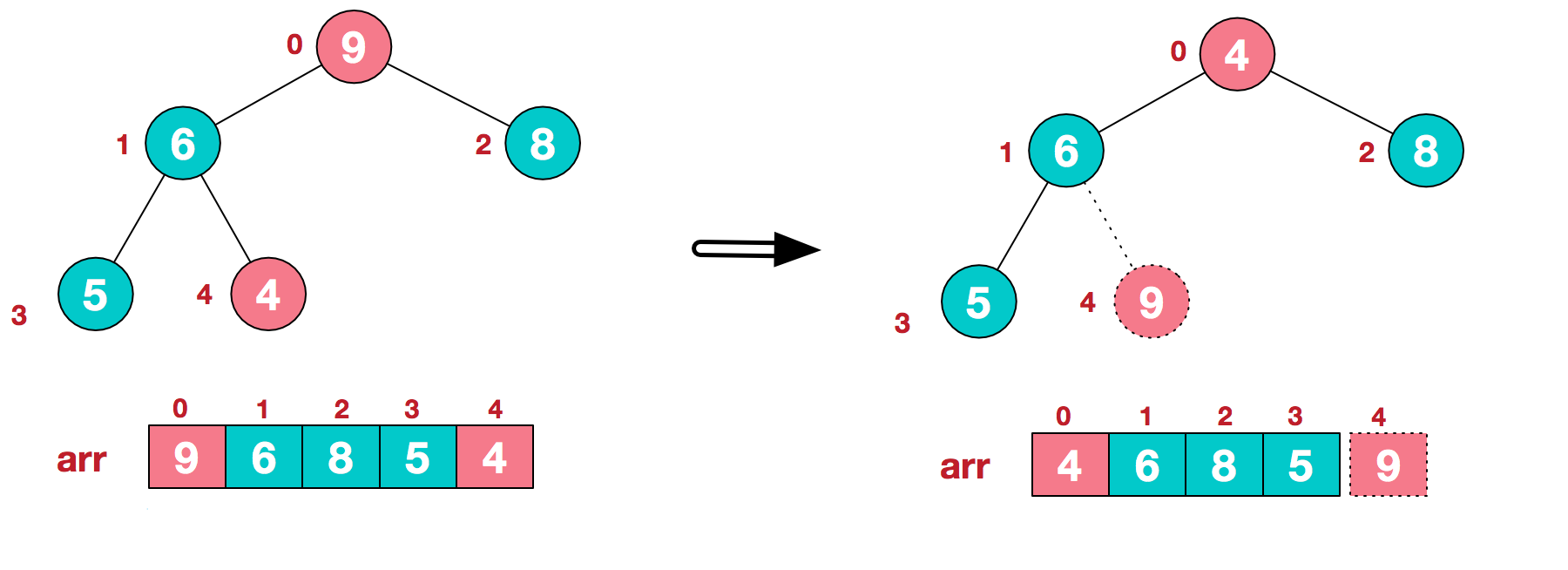
3.反复执行1、2
执行完2的交换元素后, 再执行1进行重新调整结构, 使其满足堆的定义, 然后继续执行2…反复执行至序列有序
f. 重新调整结构, 使其满足堆定义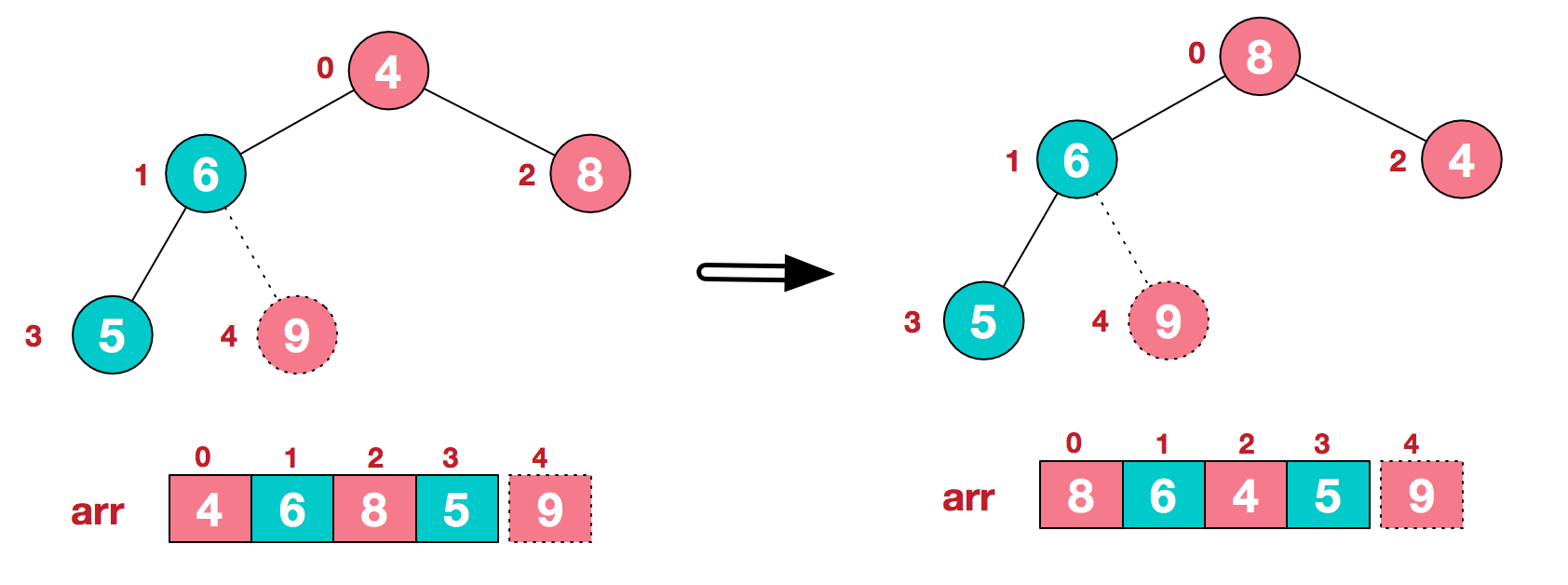
g. 再将顶堆元素8与末尾元素5进行交换, 得到第二大元素8
e. 反复执行1、2,直至序列有序
代码实现(Java)
import java.util.Arrays;
public class HeapSort {
public static void main(String[] args) {
int[] arr = {4, 6, 8, 5, 9};
heapSort(arr);
}
public static void heapSort(int[] arr) {
int temp = 0;
// 1. 将无序序列构建成一个堆, 根据升序降序需求选择大顶堆或小顶堆
for (int i = arr.length / 2 - 1; i >= 0; i--) {
adjustHeap(arr, i, arr.length);
}
// 2.将顶堆元素与末尾元素交换, 将最大元素移动到数组末端
for (int j = arr.length - 1; j > 0; j--) {
temp = arr[j];
arr[j] = arr[0];
arr[0] = temp;
adjustHeap(arr, 0, j);
}
// 3. 重新调整结构, 使其满足堆定义, 然后继续交换顶堆元素与当前末尾元素, 反复执行2,3, 直到整个序列有序
System.out.println(Arrays.toString(arr));
}
/**
* 将一个二叉树, 调整成大顶堆
* @param arr 待调整的数组
* @param i 表示非叶子结点在数组中索引
* @param length 表示对多少个元素继续调整, length是在逐渐的减少
*/
public static void adjustHeap(int[] arr, int i, int length) {
int temp = arr[i];
// 循环将以i为父结点的树的最大值放在最顶
for (int k = i * 2 + 1; k < length; k = k * 2 + 1) {
// 如果左子结点小于右子结点的值, 则k指向右子结点
if (k + 1 < length && arr[k] < arr[k + 1]) {
k++;
}
// 如果子结点大于父节点
if (arr[k] > temp) {
// 把较大值赋给当前结点
arr[i] = arr[k];
// i指向k, 继续循环比较
i = k;
} else {
break;
}
}
// 将temp值放到调整后的位置
arr[i] = temp;
}
}
哈夫曼树(Huffman Tree)
概念
结点的权: 有某种现实含义的数值(如:表示结点的重要性等)
结点的带权路径长度:从树的根到该结点的路径长度(经过的边数)与该结点上的权值的乘机,简言之就是经过的边数*权值
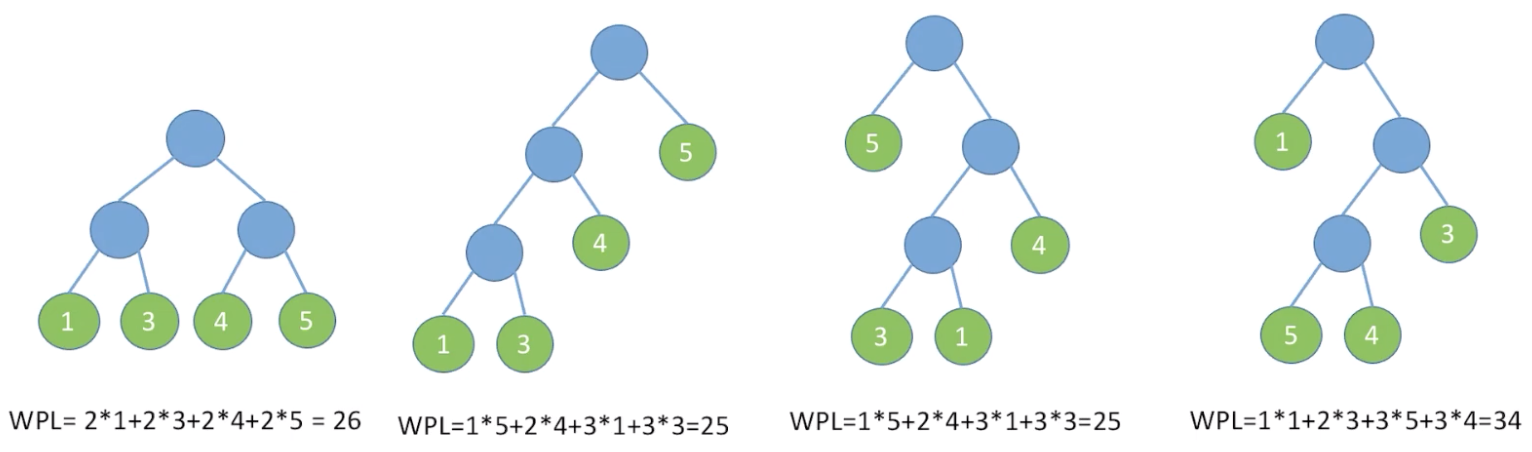
树的带权路径长度:树中所有叶结点的带权路径长度之和(WPL, Weighted Path Length)
在含有n个带权叶结点的二叉树中,其中带权路径长度(WPL)最小的二叉树称为哈夫曼树,也称最优二叉树
下图中的第二和第三颗二叉树就是哈夫曼树
构造哈夫曼树
算法思路
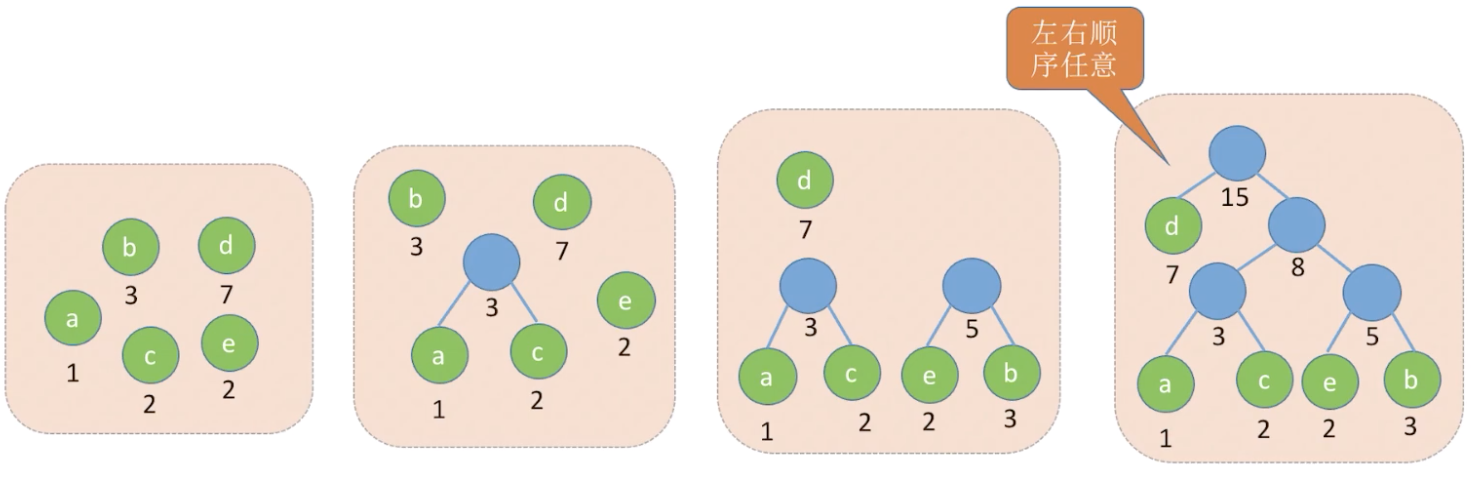
给定个权值分别为的结点,构造哈夫曼树的算法描述如下:
(1)将这个结点分别作为棵仅含一个结点的二叉树,构成森林
(2)构造一个新结点,从中选取两颗根结点权值最小的树作为新结点的左、右子树,并且将新结点的权值置为左、右子树上根结点的权值之和
(3)从中删除刚才选出的两棵树,同时将新得到的树加入中
(4)重复(2)和(3),直至中只剩下一棵树为止
如下图:
代码实现
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class HuffmanTree {
public static void main(String[] args) {
int[] arr = {1, 3, 2, 2, 7};
HuffmanNode root = createHuffmanTree(arr);
preOrder(root); // 15 7 8 3 1 2 5 2 3
System.out.println();
midOrder(root); // 7 15 1 3 2 8 2 5 3
}
public static HuffmanNode createHuffmanTree(int[] arr) {
List<HuffmanNode> huffmanNodes = new ArrayList<>();
for (int i : arr) {
huffmanNodes.add(new HuffmanNode(i));
}
while(huffmanNodes.size() > 1) {
Collections.sort(huffmanNodes);
HuffmanNode parentNode = new HuffmanNode(huffmanNodes.get(0).value + huffmanNodes.get(1).value);
parentNode.left = huffmanNodes.get(0);
parentNode.right = huffmanNodes.get(1);
huffmanNodes.add(parentNode);
huffmanNodes.remove(parentNode.left);
huffmanNodes.remove(parentNode.right);
}
return huffmanNodes.get(0);
}
public static void preOrder(HuffmanNode node) {
if (node == null) {
return;
}
System.out.print(node.value + " ");
preOrder(node.left);
preOrder(node.right);
}
public static void midOrder(HuffmanNode node) {
if (node == null) {
return;
}
midOrder(node.left);
System.out.print(node.value + " ");
midOrder(node.right);
}
}
class HuffmanNode implements Comparable<HuffmanNode> {
int value;
HuffmanNode left;
HuffmanNode right;
public HuffmanNode(int value) {
this.value = value;
}
@Override
public int compareTo(HuffmanNode o) {
return this.value - o.value;
}
@Override
public String toString() {
return "HuffmanNode{" +
"value=" + value +
", left=" + left +
", right=" + right +
'}';
}
}
哈夫曼编码(Huffman Coding)
简介
- 霍夫曼编码(英语:Huffman Coding),又译为哈夫曼编码、赫夫曼编码,是一种用于无损数据压缩的熵编码(权编码)算法。由美国计算机科学家大卫·霍夫曼(David Albert Huffman)在1952年发明。
- Huffman编码是可变长(VLC)编码的一种, Huffman编码是前缀编码.
- 固定长度编码: 每个字符用相等长度的二进制位表示
- 可变长度编码(VLC): 允许对不同字符用不等长的二进制位表示
- 前缀编码(prefix code): 任何字符的编码都不是另一字符编码的前缀, 即可做到无二义地解码
例子:
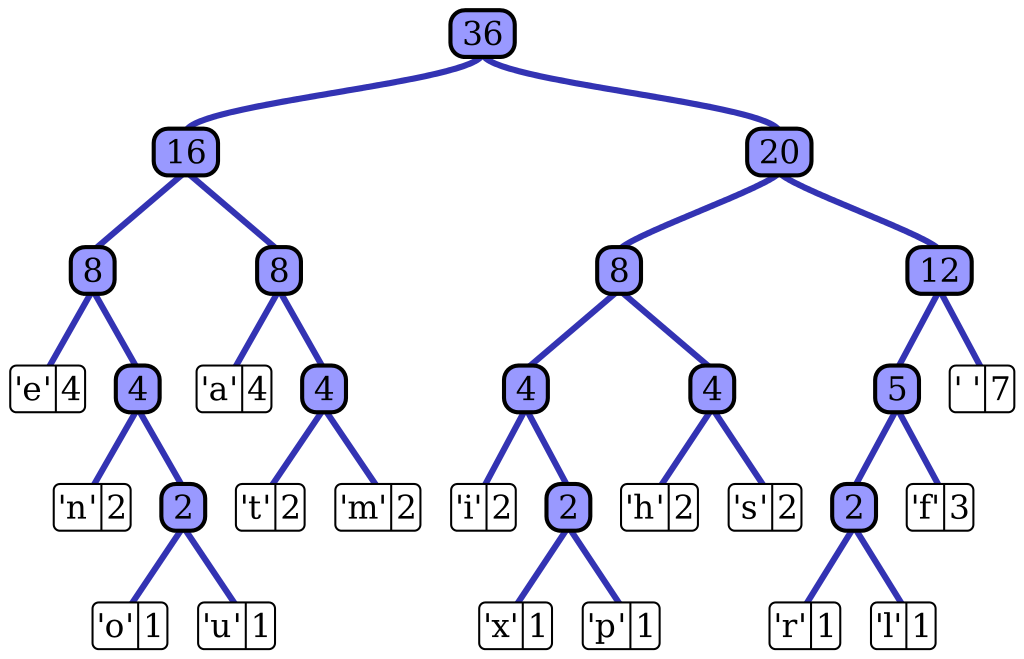
这个句子“this is an example of a huffman tree”中得到的字母频率来构建哈夫曼树。句中字母的编码和频率如图所示。编码此句子需要135 bit(不包括保存树所用的空间)
| 字母 | 频率 | 编码 |
|---|---|---|
| space | 7 | 111 |
| a | 4 | 010 |
| e | 4 | 000 |
| f | 3 | 1101 |
| h | 2 | 1010 |
| i | 2 | 1000 |
| m | 2 | 0111 |
| n | 2 | 0010 |
| s | 2 | 1011 |
| t | 2 | 0110 |
| l | 1 | 11001 |
| o | 1 | 00110 |
| p | 1 | 10011 |
| r | 1 | 11000 |
| u | 1 | 00111 |
| x | 1 | 10010 |
算法思路
- 统计字符串各个字符对应的个数
- 对照字符出现的次数构建一颗哈夫曼树, 次数作为权值
- 从小到大进行排序, 将每一个数据, 每个数据都是一个节点, 每个节点可以看成是一颗最简单的二叉树
- 取出根结点权值最小的两颗二叉树组成一颗新的二叉树, 该新的二叉树的根节点的权值是前面两颗二叉树根节点权值的和
- 再将这颗新的二叉树以根节点的权值大小再次排序, 不断重复a-b-c, 直至数列中所有数据都处理完毕构建成哈夫曼树
- 根据哈夫曼树给各个字符进行规定编码(前缀编码), 向左的路径为0, 向右的路径为1
- 对字符串进行哈夫曼编码处理:
- 编码(压缩)
- 将哈夫曼码的字符串
str的长度对8取余((str.length()+7)/8)得到长度len - 创建长度为
len的字节数组huffmanCodeBytes用于存放压缩的数据 - 以跨度为8循环遍历
str, 将取出的每8个子字符串(bit)转化为字节类型并放入huffmanCodeBytes中
- 将哈夫曼码的字符串
- 解码(解压)
- 将经过哈夫曼编码的字节数组转换成二进制字符串
- 遍历二进制字符串对照Huffman编码表进行解码(需要将字节转换成二进制的字符串)
- 编码(压缩)
代码实现
import java.util.*;
public class HuffmanCoding {
static Map<Byte, String> huffmanCodesMap;
public static void main(String[] args) {
String str = "this is an example of a huffman tree";
System.out.println("source => " + Arrays.toString(str.getBytes()));
byte[] zip = huffmanZip(str.getBytes());
System.out.println("压缩哈弗曼编码后 => " + Arrays.toString(zip));
byte[] decode = decode(huffmanCodesMap, zip);
System.out.println("解码哈弗曼编码后 => " + Arrays.toString(decode));
}
/**
* 哈夫曼解码
*
* @param huffmanCodesMap 哈夫曼码表
* @param huffmanBytes 哈夫曼字节数组
* @return 解码后的字节数组
*/
private static byte[] decode(Map<Byte, String> huffmanCodesMap, byte[] huffmanBytes) {
StringBuilder stringBuilder = new StringBuilder();
// 将经过哈夫曼编码后的字节数组转换成二进制字符串
for (int i = 0; i < huffmanBytes.length; i++) {
byte b = huffmanBytes[i];
// 判断是否是最后一个字节
boolean flag = (i == huffmanBytes.length - 1);
stringBuilder.append(byteToBitString(!flag, b));
}
// 方便进行反查
Map<String, Byte> map = new HashMap<String, Byte>();
for (Map.Entry<Byte, String> entry : huffmanCodesMap.entrySet()) {
map.put(entry.getValue(), entry.getKey());
}
List<Byte> list = new ArrayList<>();
for (int i = 0; i < stringBuilder.length(); ) {
int count = 1;
Byte b;
while (true) {
String key = stringBuilder.substring(i, i + count);
if ((b = map.get(key)) == null) {
count++;
} else {
break;
}
}
list.add(b);
i += count;
}
byte[] b = new byte[list.size()];
for (int i = 0; i < b.length; i++) {
b[i] = list.get(i);
}
return b;
}
/**
* 将字节转换成二进制的字符串
*
* @param flag 是否需要补高位, true为需要补高位, false则不补(最后一个字节则无需补高位)
* @param b byte
* @return 二进制字符串
*/
private static String byteToBitString(boolean flag, byte b) {
int temp = b;
if (flag) {
temp |= 256;
}
String str = Integer.toBinaryString(temp);
if (flag) {
return str.substring(str.length() - 8);
} else {
return str;
}
}
/**
* 哈夫曼编码压缩
*
* @param bytes 待压缩的字节数组
* @return 压缩后的字节数组
*/
private static byte[] huffmanZip(byte[] bytes) {
Map<Byte, Integer> countMap = new HashMap<>();
for (byte c : bytes) {
if (countMap.containsKey(c)) {
countMap.put(c, countMap.get(c) + 1);
} else {
countMap.put(c, 1);
}
}
HuffmanNode huffmanTreeRootNode = HuffmanTree.createHuffmanTree(countMap);
Map<Byte, String> codeMap = getCodeMap(huffmanTreeRootNode);
// 放到全局变量中, 方便调用测试
huffmanCodesMap = codeMap;
// 将各个字符进行哈夫曼编码
StringBuilder compressedStr = new StringBuilder();
for (byte b : bytes) {
compressedStr.append(codeMap.get(b));
}
// 对哈夫曼编码进行压缩
return zip(compressedStr.toString(), codeMap);
}
/**
* 压缩哈弗曼编码
*
* @param huffmanCodeStr 哈夫曼编码后的字符串
* @param codeMap 哈弗曼编码表
* @return
*/
private static byte[] zip(String huffmanCodeStr, Map<Byte, String> codeMap) {
// 对8取余
int len = (huffmanCodeStr.length() + 7) / 8;
byte[] huffmanCodeBytes = new byte[len];
for (int i = 0, index = 0; i < huffmanCodeStr.length(); i += 8, index++) {
String strByte;
if (i + 8 > huffmanCodeStr.length()) {
strByte = huffmanCodeStr.substring(i);
} else {
strByte = huffmanCodeStr.substring(i, i + 8);
}
// !!!难点!!!
huffmanCodeBytes[index] = (byte) Integer.parseInt(strByte, 2);
}
return huffmanCodeBytes;
}
/**
* 获取哈夫曼编码表
*
* @param root 哈夫曼树头结点
* @return 编码表
*/
private static Map<Byte, String> getCodeMap(HuffmanNode root) {
Map<Byte, String> map = new HashMap<>();
getRouteToMap(root, "", new StringBuilder(), map);
return map;
}
/**
* 递归获取路径
*
* @param node 哈夫曼树节点
* @param code 0表示左, 1表示右
* @param sb 拼接的路径
* @param map 最终形成的哈弗曼编码表
*/
private static void getRouteToMap(HuffmanNode node, String code, StringBuilder sb, Map<Byte, String> map) {
StringBuilder stringBuilder = new StringBuilder(sb);
stringBuilder.append(code);
if (node == null) {
return;
}
if (node.left == null && node.right == null) {
// 是叶子结点
map.put(node.data, stringBuilder.toString());
return;
}
getRouteToMap(node.left, "0", stringBuilder, map);
getRouteToMap(node.right, "1", stringBuilder, map);
}
}
class HuffmanTree {
public static HuffmanNode createHuffmanTree(Map<Byte, Integer> countMap) {
List<HuffmanNode> huffmanNodes = new ArrayList<>();
for (Byte data : countMap.keySet()) {
Integer height = countMap.get(data);
huffmanNodes.add(new HuffmanNode(data, height));
}
while (huffmanNodes.size() > 1) {
Collections.sort(huffmanNodes);
HuffmanNode parentNode = new HuffmanNode(huffmanNodes.get(0).height + huffmanNodes.get(1).height);
parentNode.left = huffmanNodes.get(0);
parentNode.right = huffmanNodes.get(1);
huffmanNodes.add(parentNode);
huffmanNodes.remove(parentNode.left);
huffmanNodes.remove(parentNode.right);
}
return huffmanNodes.get(0);
}
}
class HuffmanNode implements Comparable<HuffmanNode> {
Byte data;
int height;
HuffmanNode left;
HuffmanNode right;
@Override
public int compareTo(HuffmanNode o) {
return this.height - o.height;
}
public HuffmanNode(int height) {
this.height = height;
}
public HuffmanNode(Byte data, int height) {
this.data = data;
this.height = height;
}
@Override
public String toString() {
return "HuffmanNode{" +
"data=" + data +
", height=" + height +
", left=" + left +
", right=" + right +
'}';
}
}
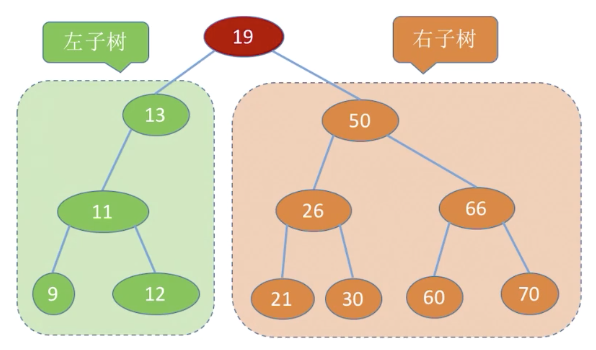
二叉排序树(BST)
概念
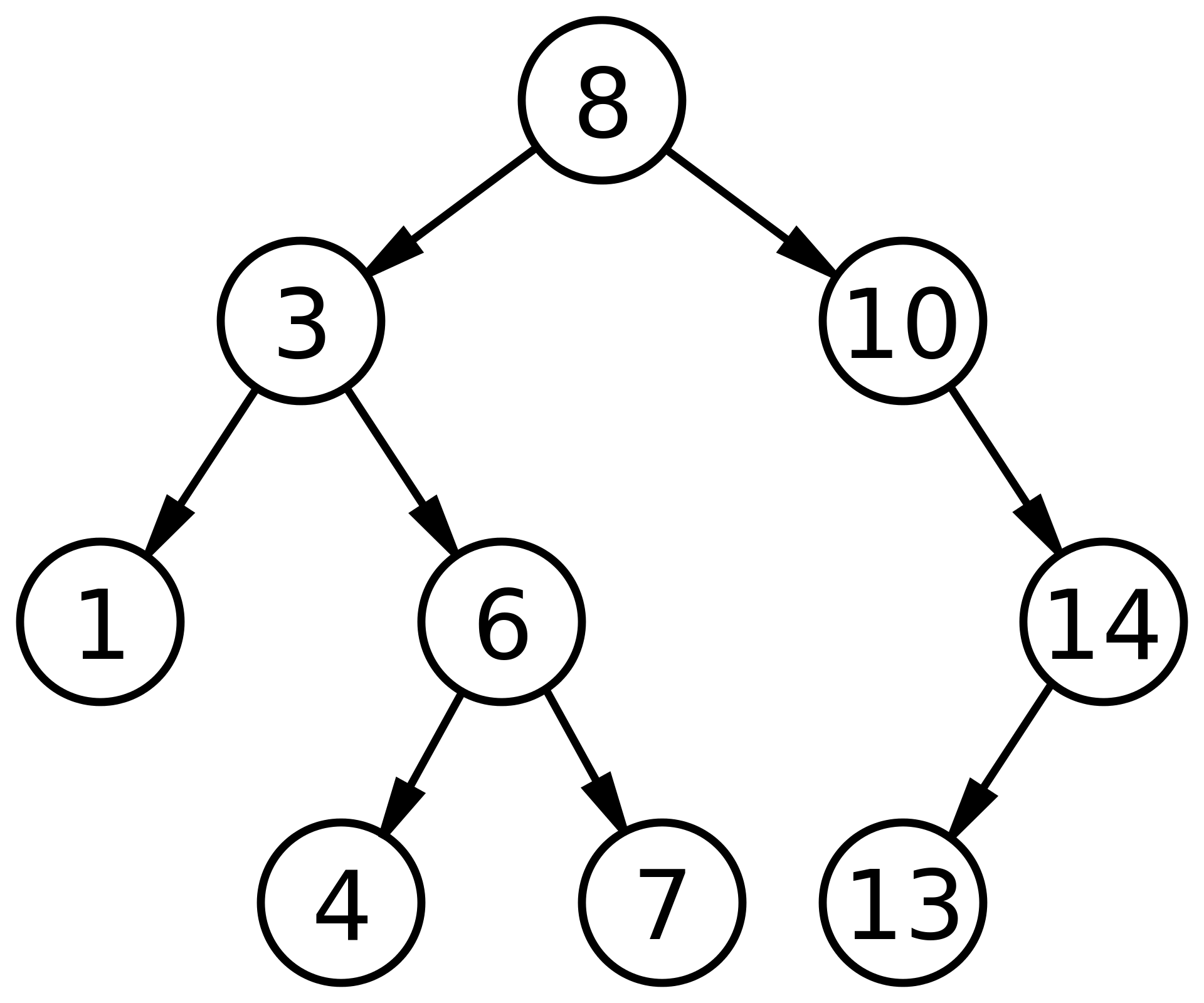
-
二叉排序树(Binary Sort Tree), 也称为有序二叉树(ordered binary tree)或二叉查找树(Binary Search Tree), 是一颗空树或具有以下性质的二叉树:
- 若任意若任意节点的左子树不空,则左子树上所有节点的值均小于它的根节点的值;
- 若任意节点的右子树不空,则右子树上所有节点的值均大于它的根节点的值;
- 任意节点的左、右子树也分别为二叉查找树;
-
BST相比于其他数据结构的优势在于查找、插入的时间复杂度较低。为。 | 算法 | 平均 | 最差 | | --- | --- | --- | | 空间 | O(n) | O(n) | | 搜索 | O(log n) | O(n) | | 插入 | O(log n) | O(n) | | 删除 | O(log n) | O(n) |
-
BST是基础性数据结构,用于构建更为抽象的数据结构,如集合、多重集、关联数组等。
插入
我们将要插入的结点称为node, 则插入node
- 如果node为空则直接返回
- 如果当前要插入节点
查找
- 如果当前node为空, 则搜索失败
- 如果要搜索的值等于当前node的值, 则查找成功
- 如果当前node的值>要搜索的值, 则搜索左子树; 否则搜索右子树
删除
BST的删除情况比较复杂, 有下面三种情况需要考虑
-
**删除叶子节点(比如1, 4, 7, 13) **
- 先找到要删除的节点
targetNode - 找到
targetNode的父节点parent - 判断
targetNode是parent的左还是右子节点对应删除
- 先找到要删除的节点
-
删除只有一颗子树的节点(比如14)
- 先找到要删除的节点
targetNode - 找到
targetNode的父节点parent - 确定
targetNode的子节点是左子节点还是子节点 - 确定
targetNode是parent的左子节点还是右子节点 - 如果targetNode有左子节点
-
如果
targetNode是parent的**左子节点 **=>parent.left = targetNode.left; -
如果
targetNode是parent的右子节点 =>parent.right = targetNode.left;
-
- 如果targetNode有右子节点
-
如果
targetNode是parent的左子节点 =>parent.left = targetNode.right; -
如果
targetNode是parent的右子节点 =>parent.right = targetNode.right;
-
- 先找到要删除的节点
-
删除两颗子树的节点(比如8, 3, 6)
- 先找到要删除的节点
targetNode - 找到
targetNode的父节点parent - 从
targetNode的右子树中找到最小的节点(中序遍历) - 用一个临时变量将最小节点的值保存并删除该结点
- targetNode.value = temp
- 先找到要删除的节点
代码实现
public class BinarySearchTree {
private BSTNode root = null;
public void add(BSTNode node) {
if (this.root == null) {
// root is empty then put the node.
this.root = node;
} else {
this.root.add(node);
}
}
public BSTNode searchParent(int targetVal) {
return searchParent(targetVal, this.root);
}
/**
* find the parent node of the target node
*
* @param targetVal Value of the target node
* @param node BST node
* @return Parent node of the target
*/
private BSTNode searchParent(int targetVal, BSTNode node) {
if (node == null) {
return null;
}
if ((node.left != null && node.left.value == targetVal) || (node.right != null && node.right.value == targetVal)) {
return node;
}
if (targetVal < node.value) {
return searchParent(targetVal, node.left);
} else if (targetVal > node.value) {
return searchParent(targetVal, node.right);
}
return null;
}
public BSTNode search(int targetVal) {
return search(this.root, targetVal);
}
private BSTNode search(BSTNode node, int targetVal) {
if (node == null) {
return null;
}
if (node.value == targetVal) {
return node;
}
if (node.value > targetVal) {
return search(node.left, targetVal);
} else {
return search(node.right, targetVal);
}
}
public BSTNode searchMinNode(BSTNode node) {
if (node.left == null) {
return node;
}
return searchMinNode(node.left);
}
public void delete(int value) {
BSTNode targetNode = search(value);
if(targetNode == null) {
System.out.println("Cannot found target node.");
return;
}
// Only one node.
if(root.left == null && root.right == null) {
root = null;
return;
}
BSTNode parent = searchParent(value);
// case 1: target node is the leaf node.
if (targetNode.left == null && targetNode.right == null) {
if (parent.left == targetNode) {
parent.left = null;
} else if (parent.right == targetNode) {
parent.right = null;
} else {
System.out.println("delete fail(case 1)");
}
return;
}
// case 2: target node has only left or right child tree.
if (targetNode.left != null && targetNode.right == null) {
if (parent.left == targetNode) {
parent.left = targetNode.left;
} else if (parent.right == targetNode) {
parent.right = targetNode.left;
} else {
System.out.println("delete fail(case 2)");
}
return;
}
if (targetNode.right != null && targetNode.left == null) {
if (parent.left == targetNode) {
parent.left = targetNode.right;
} else if (parent.right == targetNode) {
parent.right = targetNode.right;
} else {
System.out.println("delete fail(case 2)");
}
return;
}
// case 3: target node has two child tree.
if (targetNode.left != null && targetNode.right != null) {
BSTNode minNode = searchMinNode(targetNode.right);
int minVal = minNode.value;
BSTNode minNodeParent = searchParent(minNode.value);
// delete min node.
delete(minNode.value);
// assign the value of min node of the right child tree to the target node.
targetNode.value = minVal;
}
}
public static void main(String[] args) {
BinarySearchTree bst = new BinarySearchTree();
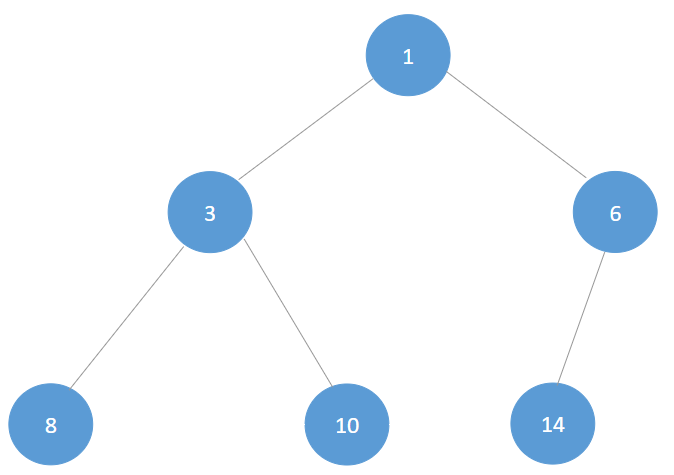
int[] arr = {8, 3, 10, 1, 6, 14, 4, 7, 13};
for (int i : arr) {
bst.add(new BSTNode(i));
}
bst.delete(6);
System.out.println(bst.root);
}
}
class BSTNode {
int value;
/**
* left child tree
*/
BSTNode left;
/**
* right child tree
*/
BSTNode right;
public BSTNode(int value) {
this.value = value;
}
/**
* insert node
*
* @param node node to insert
*/
public void add(BSTNode node) {
if (node == null) {
return;
}
// judge whether the value of the target node is smaller than the value of the current node.
if (node.value < this.value) {
if (this.left == null) {
this.left = node;
} else {
this.left.add(node);
}
} else {
if (this.right == null) {
this.right = node;
} else {
this.right.add(node);
}
}
}
@Override
public String toString() {
return "BSTNode{" +
"value=" + value +
", left=" + left +
", right=" + right +
'}';
}
}
平衡二叉树(AVL树)
概念
- 自平衡二叉查找树, 简称平衡树(AVL树, Adelson-Velsky and Landis Tree)
- 树上任一结点的左子树和右子树高度只差不超过1
- 结点的平衡因子 = 左子树高 - 右子树高
- 平衡二叉树的常用实现方法有红黑树、AVL、替罪羊树、Treap、伸展树等。 | 算法 | 平均 | 最差 | | --- | --- | --- | | 空间 | O(n) | O(n) | | 搜索 | O(log n) | O(log n) | | 插入 | O(log n) | O(log n) | | 删除 | O(log n) | O(log n) |
插入操作
- AVL树和二叉排序树一样,找到合适的位置插入
- 新插入的结点可能导致其祖先们平衡因子改变,导致失衡
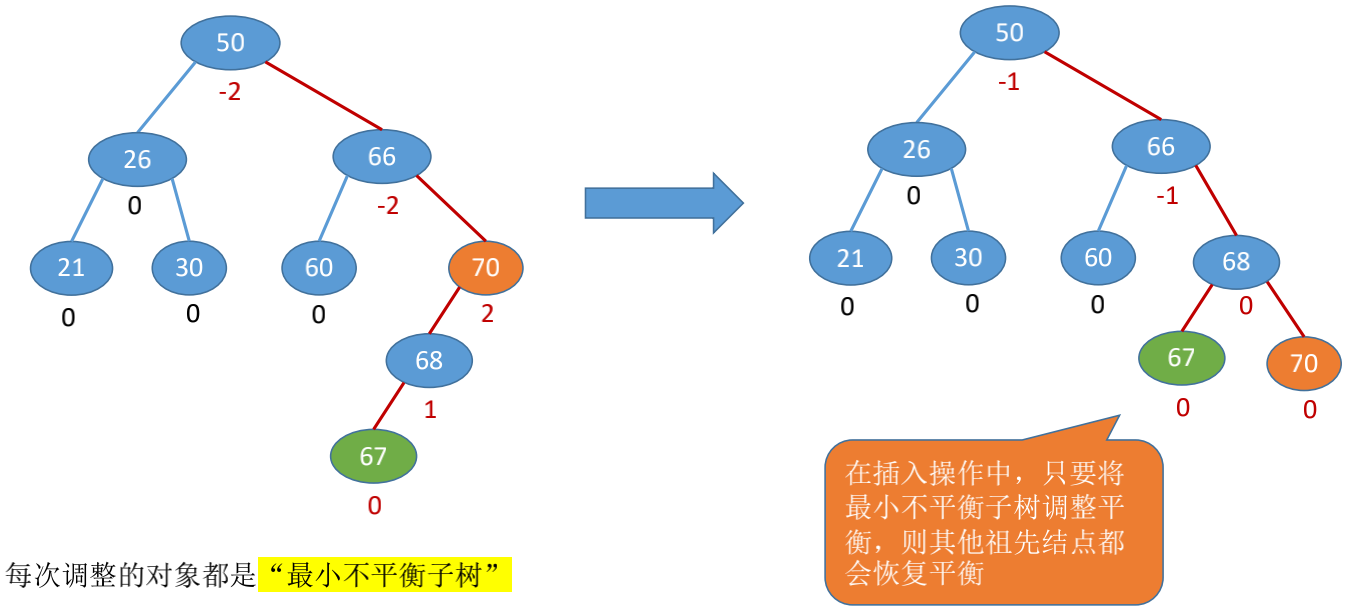
调整”不平衡”

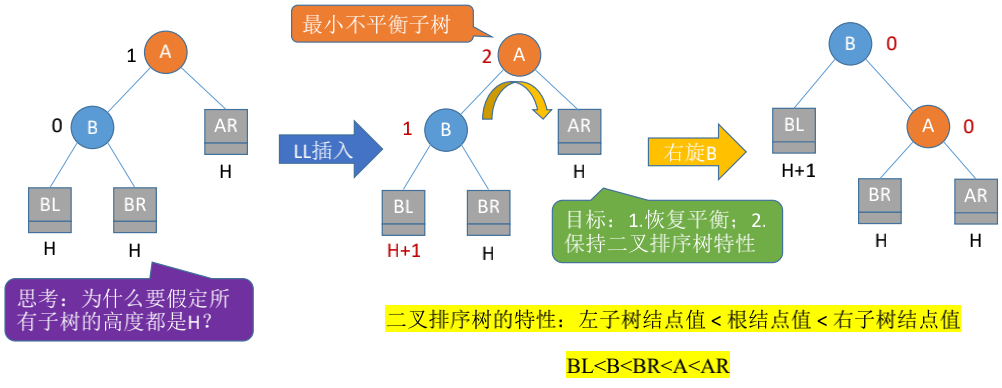
找到最小不平衡子树进行调整, 记最小不平衡子树的根为A, 则:
| 位置 | 调整 |
|---|---|
| LL(在A的左孩子的左子树中插入导致不平衡) | 将A的左孩子右上旋 |
| RR(在A的右孩子的右子树中插入导致不平衡) | 将A的右孩子左上旋 |
| LR(在A的左孩子的右子树中插入导致不平衡) | 将A的左孩子的右孩子 先左上旋再右上旋 |
| RL(在A的右孩子的左子树中插入导致不平衡) | 将A的右孩子的左孩子 先右上旋再左上旋 |
左旋
- 创建一个新的结点
newNode, 其值为最小不平衡子树的根结点的值(以下都称为当前结点) - 把
newNode的左子树设置成当前结点的左子树 - 把
newNode的右子树设置成当前结点的右子树的左子树 - 把当前结点的值换成右子树的值
- 把当前结点的右子树设置成右子树的右子树
- 把当前结点的左子树设置成
newNode
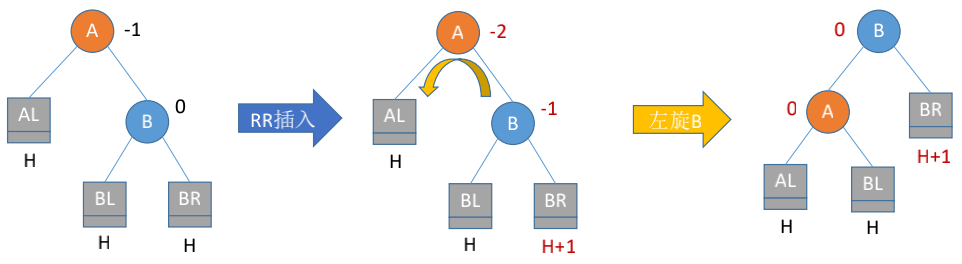
右旋
- 创建一个新的结点
newNode, 其值为最小不平衡子树的根结点的值(以下都称为当前结点) - 把
newNode的右子树设置成当前结点的右子树 - 把
newNode的左子树设置成当前结点的左子树的右子树 - 把当前结点的值换成左子树的值
- 把当前结点的左子树设置成左子树的右子树
- 把当前结点的右子树设置成
newNode
代码实现
public class AVLTree<T extends Comparable<T>> {
private AVLNode<T> root;
public AVLNode<T> search(T targetVal) {
return search(this.root, targetVal);
}
private AVLNode<T> searchParent(T targetVal) {
return searchParent(targetVal, this.root);
}
public void addNode(AVLNode<T> node) {
if (node == null) {
return;
}
if (this.root == null) {
this.root = node;
return;
}
AVLNode<T> parentNode = searchParent(node.value, root);
int cmp = node.value.compareTo(parentNode.value);
if (cmp > 0) {
parentNode.right = node;
} else {
parentNode.left = node;
}
// adjust imbalance
if (Math.abs(getLeftTreeHeight() - getRightTreeHeight()) > 1) {
AVLNode<T> minImbalanceNode = searchParent(parentNode.value);
if (minImbalanceNode.left == parentNode && parentNode.left == node) {
// LL
rotateRight(minImbalanceNode);
} else if (minImbalanceNode.right == parentNode && parentNode.right == node) {
// RR
rotateLeft(minImbalanceNode);
} else if (minImbalanceNode.left == parentNode && parentNode.right == node) {
// LR
rotateLeft(minImbalanceNode);
rotateRight(minImbalanceNode);
} else if (minImbalanceNode.right == parentNode && parentNode.left == node) {
// RL
rotateRight(minImbalanceNode);
rotateLeft(minImbalanceNode);
}
}
}
private AVLNode<T> search(AVLNode<T> node, T targetVal) {
if (node == null) {
return null;
}
int cmp = node.value.compareTo(targetVal);
if (cmp == 0) {
return node;
}
if (cmp > 0) {
return search(node.left, targetVal);
} else {
return search(node.right, targetVal);
}
}
private AVLNode<T> searchParent(T targetVal, AVLNode<T> node) {
if (node == null) {
return null;
}
int cmp = targetVal.compareTo(node.value);
if ((node.left != null && node.left.value == targetVal) ||
(node.right != null && node.right.value == targetVal)) {
return node;
}
if (cmp < 0) {
if (node.left == null) {
return node;
}
return searchParent(targetVal, node.left);
} else if (cmp > 0) {
if (node.right == null) {
return node;
}
return searchParent(targetVal, node.right);
}
return null;
}
public int getTreeHeight(AVLNode<T> node) {
if (node == null) {
return 0;
}
return Math.max(getTreeHeight(node.left), getTreeHeight(node.right)) + 1;
}
public int getLeftTreeHeight() {
return getTreeHeight(this.root.left);
}
public int getRightTreeHeight() {
return getTreeHeight(this.root.right);
}
public void rotateLeft(AVLNode<T> node) {
AVLNode<T> newNode = new AVLNode<>(node.value);
newNode.left = node.left;
newNode.right = node.right.left;
node.value = node.right.value;
node.right = node.right.right;
node.left = newNode;
}
public void rotateRight(AVLNode<T> node) {
AVLNode<T> newNode = new AVLNode<>(node.value);
newNode.right = node.right;
newNode.left = node.left.right;
node.value = node.left.value;
node.left = node.left.left;
node.right = newNode;
}
public static void main(String[] args) {
int[] arr = {50, 26, 66, 21, 30, 60, 70, 68, 67, 99, 88, 41, 22, 55, 61, 46, 46, -10, 4, 55, 99, 46 ,40};
AVLTree<Integer> tree = new AVLTree<>();
for (int i : arr) {
tree.addNode(new AVLNode<>(i));
}
System.out.println(tree.root);
System.out.println(tree.search(70));
System.out.println(tree.getLeftTreeHeight());
System.out.println(tree.getRightTreeHeight());
}
}
class AVLNode<T extends Comparable<T>> {
T value;
AVLNode<T> left;
AVLNode<T> right;
public AVLNode(T value) {
this.value = value;
}
@Override
public String toString() {
return "AVLNode{" +
"value=" + value +
", left=" + left +
", right=" + right +
'}';
}
}