关于词法分析器
词法分析器
我们可以知道词法分析器的输入是源程序,输出的是一个记号,当词法分析器从左到右一个一个读入源程序的时候,会对每个词素进行归类,例如:
if(a > 0) {
b = a + 1;
} else {
b = a - 1;
}
printf("b is:%d", b);
在上面代码中词素指的是if, a 等等,以及我们看不见的空格和换行符,就是最小的有意义单位。当词法分析器读到 if 的时候,就会将其认定为保留字,然后再读( 将其认定为左括号,再读到a,将其认定为标识符(identity)。
如何实现
目前比较主流的实现词法分析器的方法有两种:
- 手工编码
- 自动生成
所谓手工编码其实就是开发者手搓一个词法分析器出来,比如 GCC 和 LLVM 其实都是用的手工编码的方式实现的,这样的优点是执行效率很高,能够更加灵活地定制需求
而自动生成则是用一些专门的工具(如Lex、Flex),根据我们给定的规则去自动生成词法分析器的代码,优点显然就是时间成本低了,但比较难去控制细节
转移图
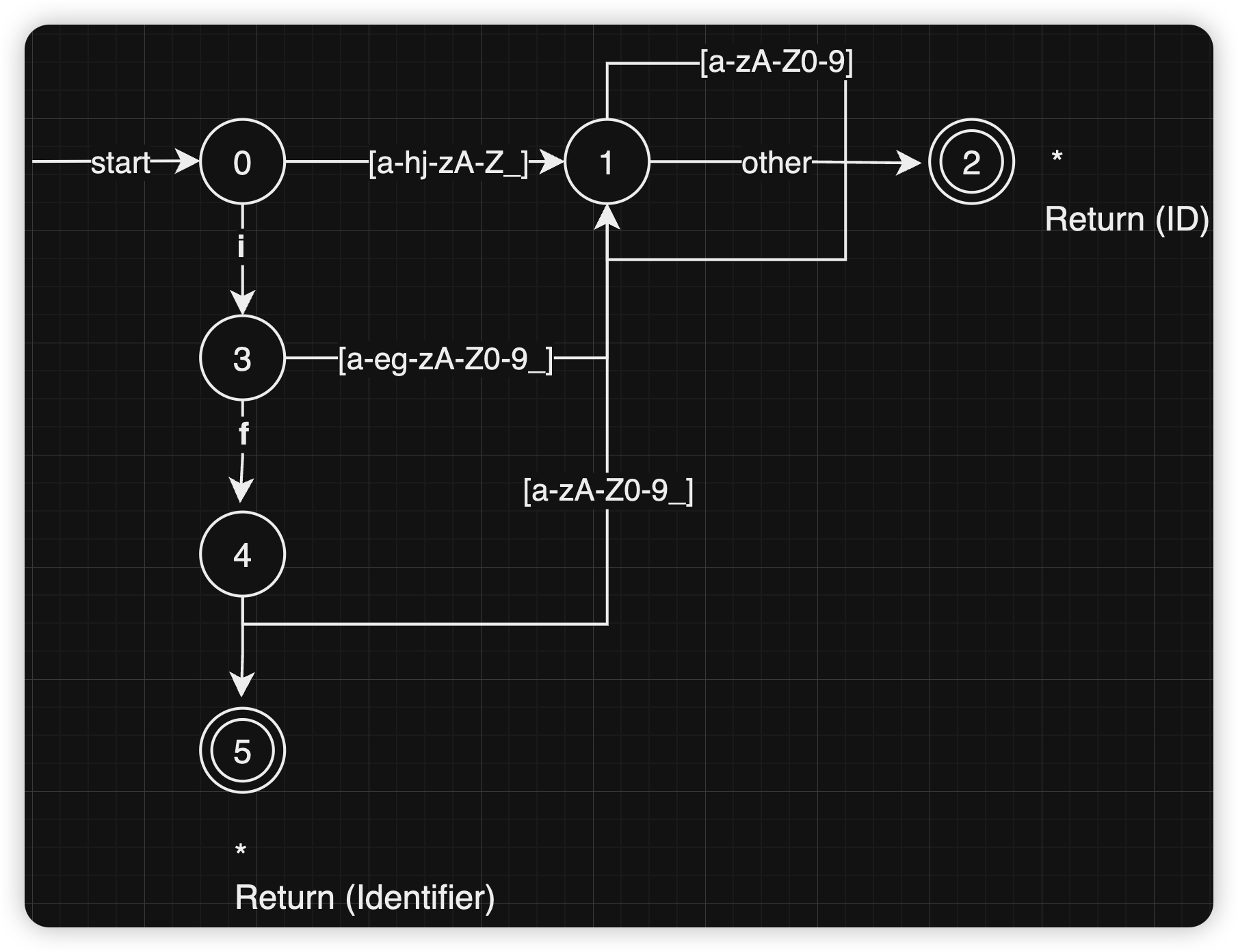
关键字表算法
- 对所有的关键字,构造出一个哈希表H。
- 对所有的标识符和关键字,先统一按标识符的转移进行识别
- 识别完成后,再进一步用哈希表 H 去分辨哪些标识符为关键字
对于关键字表,我们可以用完美哈希算法(Perfect Hashing)来实现,以达到最高的效率
完美哈希通常分为两级:
- 第一级哈希(First-Level Hash):选择或构造一个哈希函数,将关键字映射到一个较大的中间空间,目的是尽量减少冲突。
- 第二级哈希(Second-Level Hash):对于第一级哈希中出现冲突的关键字集合,为每个集合再次选择或构造一个哈希函数,确保这些关键字映射到不同的哈希值上。
实现步骤大致如下:
- 收集所有关键字:确定编程语言的所有保留关键字。
- 构造第一级哈希函数:找到一个哈希函数,使得关键字尽量均匀分布在哈希表中,并且冲突较少。
- 分析冲突:对于第一级哈希中的冲突,将冲突的关键字分到同一个组。
- 为每个组构造第二级哈希函数:对于每个冲突组,构造一个新的哈希函数,确保组内关键字不会产生冲突。
- 创建最终的哈希表:使用第一级哈希函数确定关键字的第一级索引,然后使用第二级哈希函数确定最终的哈希表中的位置。
正则表达式
语法糖
[c1-cn]== c1 | c2 | c3 | … | cne+== 一个或多个 ee?== 0 个或 1 个 e"a*"== 0 个或多个 ee{i, j}== i 到 j 个 e 的连接.== 除\n以外的任意字符
有限状态自动机(FA)
什么是串被“接受”?词法分析器开始读入字符,被状态转移函数 驱动,一个个地读入字符,直到字符读完了,并且落到的状态是在终止状态的话,就称这个串为能被自动机所接受。
确定的有限自动机(DFA)
DFA 的实现
非确定的有限自动机(NFA)
RE to NFA(Thompson 算法)
NFA to DFA(子集构造算法)
首先,为什么要将 NFA 转换为 DFA 呢?原因很简单,NFA 在实际的计算机程序中并不好实现,会导致很多回溯,这会在实现的时候增加复杂性。在大多数的词法分析器中(如 Lex),都会先将正则表达式转换为 NFA,再用子集构造算法将 NFA 转换为 DFA。
下面直接引入一个实例讲讲如何用子集构造算法(the subset construction) 将一个 NFA 转换为 DFA,其实这个算法的本质就是:维持自动机状态转移的逻辑性的同时,将一个或多个状态构造成为一个子集,用这个子集去等价地代替若干节点,在不失自动机运行逻辑的同时,消除了 转移。
举一个实例,有 NFA 如下:
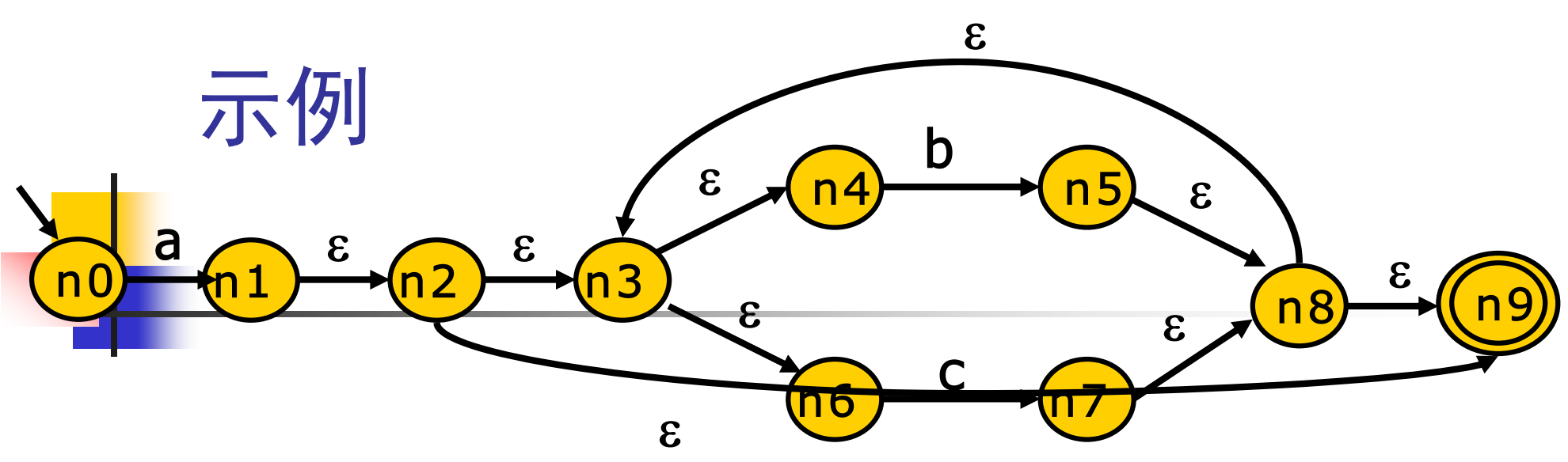
首先我们考虑从起始状态 出发,读入一个输入字符 ,也就是走 这条边,那么思考一下,可以走到哪个状态呢?
我们已知 转移,也就是走 这条边是不需要任何代价的,无需读入字符都可以进行前进达到下一个状态,那么答案显而易见。为了构造出一个新的状态机 DFA,我们令 ,从 出发,走 这条边,可以到达
令这一个可走到的状态的集合为 ,即
然后我们再从 这个新的状态集进行转移,例如 读入字符 , 都无法接受 b 这个字符,只有 可以接受 将状态转移到 ,那么可到达的状态集 则为:
接下来我们再考虑 状态集中的状态能走哪些点,会发现只有 ,可以读入一个字符 走到 ,于是乎 从 出发读入字符 可以走到的状态有:,记为:
那么从 出发走 边呢?那其实可以走到的状态集和 完全一致,我们就算作同一个状态集了,即
那 走 呢?实则又回到了自身,即
最后 同理,无论是通过 边会回到 ,走 边则会回到自身,即
最后我们用图将构造出来的子集以及状态转移表示出来,如下:
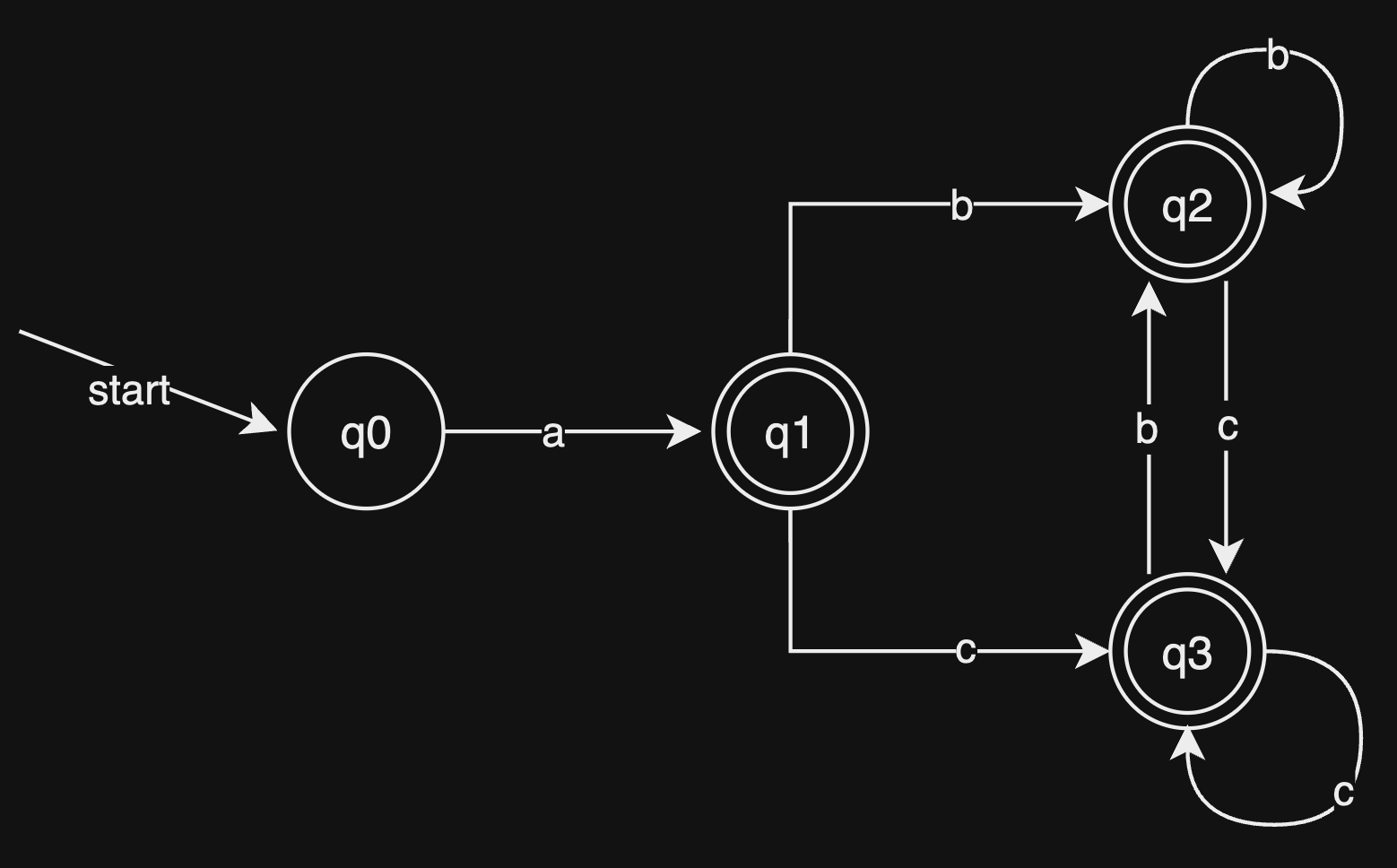
由于 中都包含了接受状态 ,所以他们都是接受状态
最小化 DFA(Hopcroft 算法)
为什么要对 DFA 进行最小化,首先我们得知道最小化是什么,我们要对 DFA 进行最小化其实就是将一些等价的状态给去掉,用共同的一个状态给予表示,以起到减少状态数量的作用。在真实计算机表示中,词法分析器一般都是对 DFA 进行模拟,而 DFA 的状态一般是用「图」的数据结构来进行表示的,节点数越少,内存甚至是 cache 的开销就越低,很可能意味着执行效率的提升。
上面我们已经讨论了如何将一个 NFA 转换为一个 DFA ,我们转换后的 DFA 状态表示其实很有冗余,可以进一步的进行优化。 接下来我们还是会针对那个 DFA 进行优化。
在开始我们的实例之前,先来个哈人的东西(Hopcroft算法的伪代码):
split(S)
foreach (character c)
if(c can split s)
split s into T1, ..., Tk
hopcroft()
split all node into N, A
while(set is still changes)
split(S)
是的,在没有任何解释的情况下,看到这串代码会直接懵逼(除非你学过),我们先直接看下面的hopcroft函数都干了些什么。
split all node into N, A ,这个的意思是将自动机的所有的状态(node)做第一次划分,划分为 N 和 A 这两个集合,N 集合为非接受状态集,S 集合为接受状态集,这里啰嗦一句,其实接收状态也就是我们看到的状态转移图中的那些两个圈的状态。
然后做一个 while 循环,直到什么时候结束呢?直到新的状态集 set 没有改变了就结束,在循环内部调用了一个划分的函数,将 S,即所有的状态集传递进去,注意是状态集。
split 函数里干的事情其实也非常简单,对每一个可能的输入字符进行一个遍历,如果字符 c 的转移能够对 S 进行切分,就将 s 切分为若干的子集 T1, ... , Tk。emm,还是有点抽象,还是来看看实例是怎么运行的吧
在这里我们再次引用下上面已经展示过的 DFA:
首先我们根据算法的思路,将这个DFA 根据接受和非接受划分为两个集合: 然后我们考虑对 进行划分,显然一个节点本身是没有等价类的,无法进一步的划分了。对于我们看有哪些可能得输入字符呢?也就是 了吧,那么对于 ,
- 读入一个 字符,它们都会转移到 这个状态,显然无需进行划分,
- 而对于读入 字符,它们都会转移到 这个状态,也无需进一步的划分了
也就是最终我们减少到了只剩下 状态,容易得知转移函数有如下: 根据这些,我们就可以画出我们优化后的 DFA 的图来了:
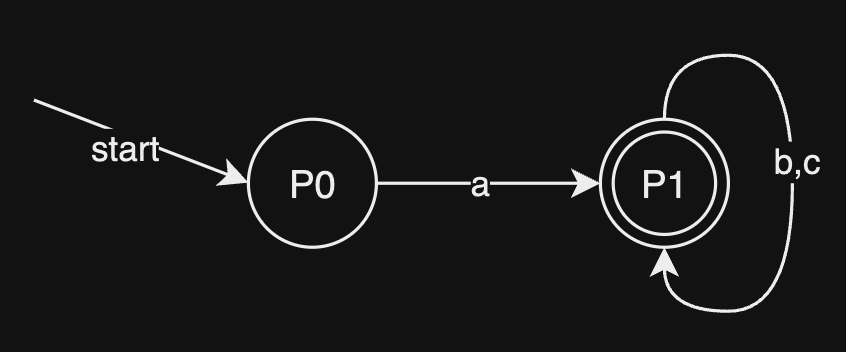
课后作业 1
题目
在这部分中,你将使用图转移算法手工实现一个小型的词法分析器。
- 分析器的输入:存储在文本文件中的字符序列,字符取自ASCII字符集。文件中可能包括四种记号:关键字if、符合C语言标准的标识符、空格符、回车符\n。
- 分析器的输出:打印出所识别的标识符的种类、及行号、列号信息。
【示例】对于下面的文本文件:
ifx if iif if
iff if
你的输出应该是:
ID(ifx) (1,1)
IF (1,5)
ID(iif) (1,8)
IF (1,18)
ID(iff) (2,1)
IF (2,9)
实现思路
- 首先词法分析器的状态转移图
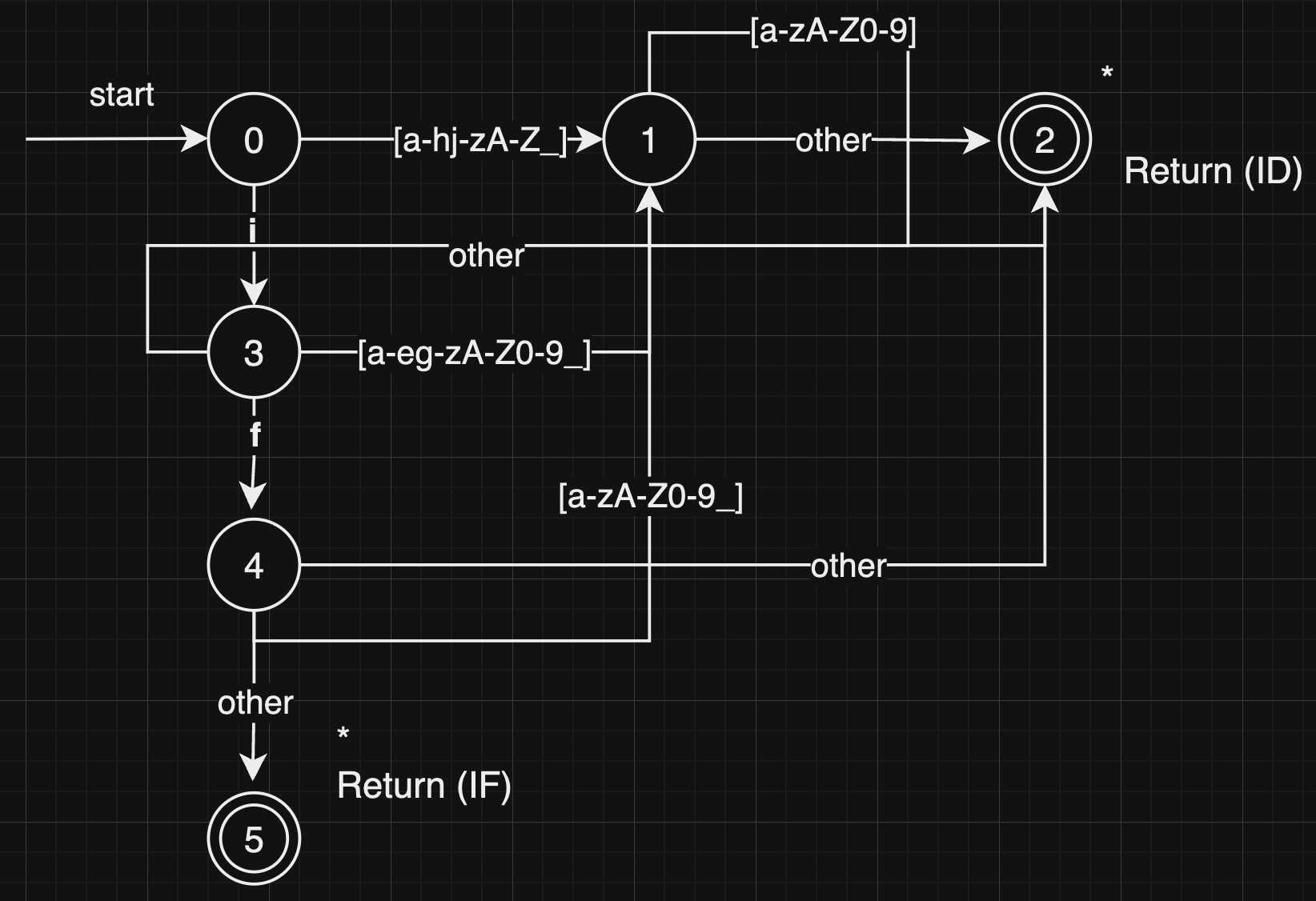
完整代码
#include <iostream>
#include <string>
#include <fstream>
#include <vector>
#include <cctype>
#define FILE_NAME "bj_hw02_text.txt"
enum State {
START,
IN_IDENTIFIER,
ACCEPT_IF,
ACCEPT_IDENTIFIER,
REJECT
};
enum Kind {
IF,
IDENTIFIER
};
struct Token {
Kind kind;
std::string lexeme;
int rowNumber;
int columnNumber;
};
class Automaton {
private:
std::vector<Token> tokens;
State currentState;
int startColumn;
public:
Automaton() : currentState(START), startColumn(0) {}
void processInputLine(const std::string &line, int rowNumber) {
currentState = START;
std::string currentLexeme;
startColumn = 1;
for (size_t i = 0; i <= line.size(); ++i) {
char c = (i < line.size()) ? line[i] : ' '; // Simulate a space at the end to flush last token
switch (currentState) {
case START:
if (c == 'i') {
currentState = IN_IDENTIFIER;
currentLexeme = c;
startColumn = i + 1;
} else if (isalpha(c) || c == '_') {
currentState = IN_IDENTIFIER;
currentLexeme = c;
startColumn = i + 1;
}
break;
case IN_IDENTIFIER:
if (isalnum(c) || c == '_') {
currentLexeme += c;
} else {
if (currentLexeme == "if") {
tokens.push_back({IF, currentLexeme, rowNumber, startColumn});
} else {
tokens.push_back({IDENTIFIER, currentLexeme, rowNumber, startColumn});
}
currentState = START;
currentLexeme.clear();
}
break;
default:
currentState = START;
break;
}
}
}
void printTokens() const {
for (const Token &token : tokens) {
std::string tokenType = (token.kind == IF) ? "IF" : "ID";
std::cout << tokenType << "(" << token.lexeme << ") (" << token.rowNumber << "," << token.columnNumber << ")" << std::endl;
}
}
};
int main() {
std::ifstream myfile(FILE_NAME);
if (!myfile.is_open()) {
std::cout << "Cannot open the file." << std::endl;
return EXIT_FAILURE;
}
Automaton automaton;
std::string line;
int currentLineNumber = 1;
while (getline(myfile, line)) {
automaton.processInputLine(line, currentLineNumber++);
}
myfile.close();
automaton.printTokens();
return EXIT_SUCCESS;
}
课后作业 2
题目
给定如下的正则表达式
(a|b)((c|d)*),请完成如下练习: (1)使用Thompson算法,将该正则表达式转换成非确定状态有限自动机(NFA); (2)使用子集构造算法,将该上述的非确定有限状态自动机(NFA)转换成确定状态有限自动机(DFA); (3)使用Hopcroft算法,对该DFA最小化。
lab
Description
设一语言的关键词、运算符、分界符的个数与单词如下:
struct { int number; string str[10]; } keywords={3,"int","main","return"} ; //关键词
struct { int number; string str[10]; } operators ={5,"+","*","=","+=","*="}; //运算符
struct { int number; string str[10]; } boundaries ={6,"(",")","{","}",",",";"} ; //分界符
struct { int number; string str[100];} identifieres={0}; //标识符
struct { int number; string str[100];} Unsigned_integer={0}; //无符号整数
- 以上类号分别为 1~5,序号从 0 开始;
- 标识符是字母开头的字母数字串;常量为无符号整数;设计一程序实现词法分析。
Input
输入一程序,结束符用#;
Output
输出单词数对:<类号,序号>。 输出标识符表,用空格分隔; 输出无符号整数表,用空格分隔;
Testcase 1
Input:
main()
{
int a=2,b=3;
return 2*b+a;
}#
Expected Output:
<1,1><3,0><3,1><3,2><1,0><4,0><2,2><5,0><3,4><4,1><2,2><5,1><3,5><1,2><5,0><2,1><4,1><2,0><4,0><3,5><3,3>
identifieres:a b
Unsigned_integer:2 3
Testcase 2
Input:
main()
{
int a=21;
int b_=3;
return 2*b_+a;
}#
Expected Output:
<1,1><3,0><3,1><3,2><1,0><4,0><2,2><5,0><3,5><1,0><4,1><2,2><5,1><3,5><1,2><5,2><2,1><4,1><2,0><4,0><3,5><3,3>
identifieres:a b_
Unsigned_integer:21 3 2
My Code
#include <iostream>
#include <string>
#include <cctype>
#include <sstream>
enum lexicalType {
KEYWORD = 1,
OPERATOR = 2,
BOUNDARY = 3,
IDENTIFIER = 4,
UNSIGNED_INTEGER = 5
};
struct Keyword {
int number;
std::string str[10];
} keywords = {3, "int", "main", "return"}; // 关键词
struct Operator {
int number;
std::string str[10];
} operators = {5, "+", "*", "=", "+=", "*="}; // 运算符
struct Boundary {
int number;
std::string str[10];
} boundaries = {6, "(", ")", "{", "}", ",", ";"}; // 分界符
struct Identifier {
int number;
std::string str[100];
} identifieres = {0}; // 标识符
struct UnsignedInteger {
int number;
std::string str[100];
} Unsigned_integer = {0}; // 无符号整数
class StateAutomaton {
public:
static int isKeyword(const std::string& word) {
for (int i = 0; i < keywords.number; ++i) {
if (keywords.str[i] == word)
return i;
}
return -1;
}
static std::string tokenize(const int type, const int ordinal) {
return "<" + std::to_string(type) + "," + std::to_string(ordinal) + ">";
}
static bool isAccept(const int state) {
std::vector<int> notAcceptState = {0, 1, 4, 7, 16};
return find(notAcceptState.begin(), notAcceptState.end(), state) == notAcceptState.end();
}
void handleError() {
state = 0;
startIdx = idx;
}
void rollback() {
idx--;
}
void printIds() const {
std::cout << std::endl << "identifieres:";
for (const auto& i: idVector) {
std::cout << i << " ";
}
std::cout << std::endl;
}
void printUnsignedInteger() const {
std::cout << "Unsigned_integer:";
for (const int i: unsignedNumberVector) {
std::cout << i << " ";
}
}
void processLine(const std::string& input) {
idx = 0;
state = 0;
startIdx = 0;
while (idx < input.size()) {
const char c = input[idx++];
if (c == '\n') {
continue;
}
switch (state) {
case 0:
if (std::isalpha(c))
state = 1;
else if (c == '=') {
state = 3;
std::cout << tokenize(OPERATOR, 2);
} else if (c == '+')
state = 4;
else if (c == '*')
state = 7;
else if (c == '(') {
state = 10;
std::cout << tokenize(3, 0);
} else if (c == ')') {
state = 11;
std::cout << tokenize(BOUNDARY, 1);
} else if (c == '{') {
state = 12;
std::cout << tokenize(BOUNDARY, 2);
} else if (c == '}') {
state = 13;
std::cout << tokenize(BOUNDARY, 3);
} else if (c == ',') {
state = 14;
std::cout << tokenize(BOUNDARY, 4);
} else if (c == ';') {
state = 15;
std::cout << tokenize(BOUNDARY, 5);
} else if (std::isdigit(c))
state = 16;
else
handleError();
break;
case 1:
if (!std::isalnum(c) && c != '_') {
// ACCEPT
state = 2;
rollback();
currentWord = input.substr(startIdx, idx - startIdx);
const int kw = isKeyword(currentWord);
if (kw != -1) {
// 是关键字
std::string out = tokenize(KEYWORD, kw);
std::cout << out;
} else {
// 是标识符
auto it = std::find(idVector.begin(), idVector.end(), currentWord);
if (it == idVector.end()) {
// 标识符未定义
std::cout << tokenize(IDENTIFIER, idVector.size());
idVector.push_back(currentWord);
} else {
// 标识符已定义过,直接引用
const int existIdx = std::distance(idVector.begin(), it);
std::cout << tokenize(IDENTIFIER, existIdx);
}
}
}
break;
case 7:
if (c == '=') {
state = 9;
std::cout << tokenize(OPERATOR, 4);
} else {
state = 8;
std::cout << tokenize(OPERATOR, 1);
rollback();
}
break;
case 4:
if (c == '=') {
state = 6;
std::cout << tokenize(OPERATOR, 3);
} else {
state = 5;
std::cout << tokenize(OPERATOR, 0);
rollback();
}
break;
case 16:
if (!std::isdigit(c)) {
// ACCEPT
state = 17;
rollback();
currentWord = input.substr(startIdx, idx - startIdx);
int unsignedNum = 0;
try {
// convert
unsignedNum = std::stoi(currentWord);
} catch (const std::invalid_argument& ia) {
std::cerr << "Invalid argument: " << ia.what() << '\n';
}
auto it = std::find(unsignedNumberVector.begin(), unsignedNumberVector.end(), unsignedNum);
if (it == unsignedNumberVector.end()) {
// Not found
std::cout << tokenize(UNSIGNED_INTEGER, static_cast<int>(unsignedNumberVector.size()));
try {
unsignedNumberVector.push_back(std::stoi(currentWord));
} catch (const std::invalid_argument& ia) {
std::cerr << "Invalid argument: " << ia.what() << '\n';
}
} else {
const int difference = std::distance(unsignedNumberVector.begin(), it);
std::cout << tokenize(UNSIGNED_INTEGER, difference);
}
}
break;
case 2:
case 3:
case 5:
case 6:
case 8:
case 9:
case 10:
case 11:
case 12:
case 13:
case 14:
case 15:
case 17:
break;
default: std::cout << "ERROR!" << std::endl;
}
if (isAccept(state)) {
// init state
state = 0;
startIdx = idx;
}
}
}
private:
int state = 0;
int idx = 0;
int startIdx = 0;
std::string currentWord;
std::vector<std::string> idVector;
std::vector<int> unsignedNumberVector;
};
int main() {
std::string line;
std::string totalInput;
StateAutomaton automaton;
while (std::getline(std::cin, line)) {
automaton.processLine(line + '\n');
if (line.find('#') != std::string::npos) {
break;
}
}
automaton.printIds();
automaton.printUnsignedInteger();
return EXIT_SUCCESS;
}