图的基本概念
图是一种复杂的非线性结构。
在线性结构中,数据元素之间满足唯一的线性关系,每个数据元素(除第一个和最后一个)只有一个直接前趋和一个直接后继;
在树形结构中,数据元素之间有明显的层次关系,并且每个数据元素只与上一层中的一个元素(parent node)及下一层的多个元素(child node)相关;
而在图形结构中,节点之间的关系是任意的,图中任意两个数据元素之间都有可能相关。
图的定义
图G由两个集合V(顶点Vertex)和E(边Edge)组成,定义为G=(V, E),其中V(G)表示图G中顶点的有限非空集;E(G)表示图G中顶点之间的关系(边)集合。若V={v1,v2,...,vn},则用 |V| 表示图G中顶点的个数,也称图G的阶, E={(u,v)∣u∈V,v∈V}, 用 |E| 表示图G中边的条数。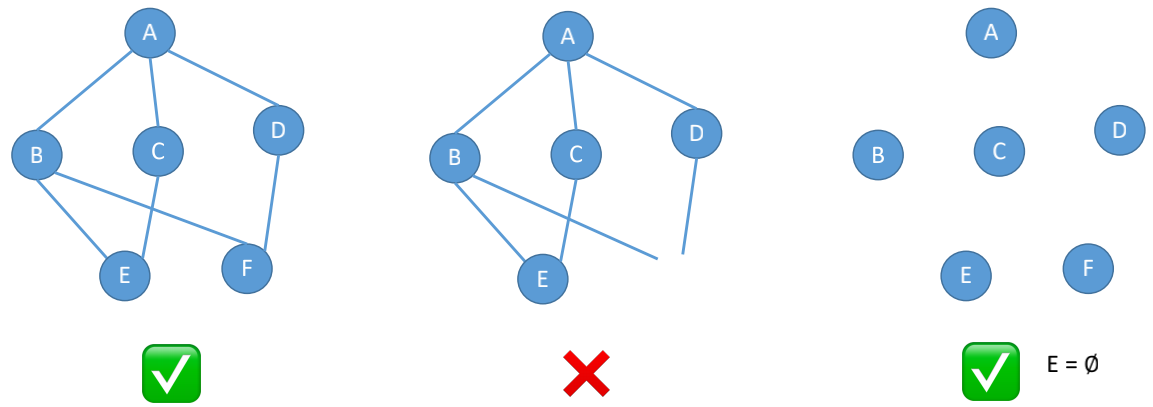
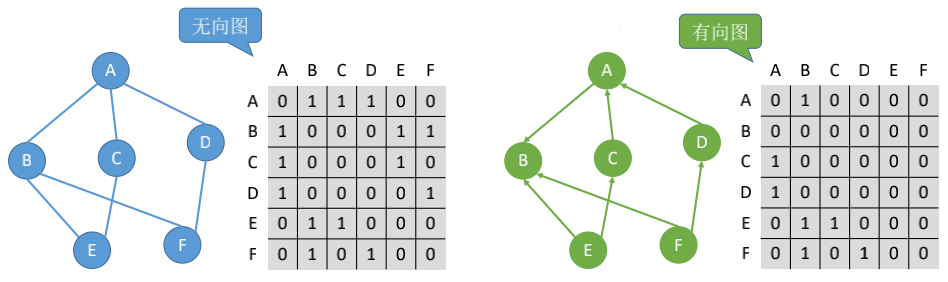
无向图(undirected graph)
若E是无向边(简称边)的有限集合时,则图G为无向图。边是顶点无序对,记成(v, w)或 (w, v), 因为**(v, w) = (w, v), 其中v, w是顶点。可以说顶点w和顶点v互为邻接点**。边(v,w)依附于顶点w和v,或者说边(v,w)和顶点v、w相关联。
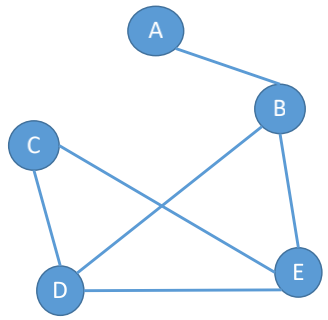
V_2=\{A,B,C,D,E\}\\
E_2=\{(A,B),(B,D),(B,E),(C,D), (C,E), (D,E)\}$$
## 有向图(directed graph)
若E是有向边(也称弧)的有限集合时,则图G为有向图(digraph)。
弧是顶点的有序对,记为$<v, w>$,其中v、w是顶点,v称为弧尾,w称为弧头,<v, w>称为从顶点v到顶点w的弧,也称v邻接到w,或w邻接自v。
$$<v,w>\neq<w,v>$$
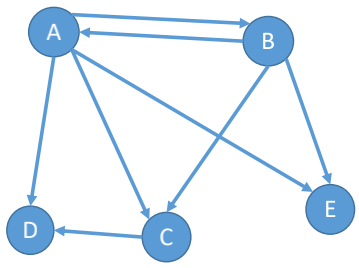
$$G_1=(v_1,E_1)\\
V_1=\{A,B,C,D,E\}\\
E_1=\{<A,B>,<A,C>, <A,D>, <A,E>, <B,A>, <B,C>, <B,E>, <C,D>\}$$
## 顶点的度、入度、出度
### 无向图
**顶点v的度**是指依附于该顶点的边的条数,记为$TD(v)$
在具有n个顶点、e条边的无向图中,$\sum\limits_{i=1}^n TD(v_i)=2e$
**即无向图的全部顶点的度的和等于边数的2倍**
### 有向图
**入度(in-degree)** 是以顶点v为终点的有向边的数目。记为$ID(v)$
**出度(out-degree)**是以顶点v为起点的有向边的数目, 记为$OD(v)$
**顶点v的度**等于其**入度和出度之和**, 即$TD(v)=ID(v)+OD(v)$
在具有n个顶点、e条边的有向图中,$\sum_{i=1}^n ID(v_i) = \sum_{i=1}^n OD(v_i)=e$
## 顶点-顶点的关系描述
- 路径: 顶点$v_p$到顶点$v_q$之间的一条路径是指顶点序列,$v_p,v_{i_1},v_{i_2}, ..., v_{i_m}, v_q$
- 回路: 第一个顶点和最后一个顶点相同的路径称为回路或环
- 简单路径: 在路径序列中, 顶点不重复出现的路径称为简单路径
- 简单回路: 除第一个顶点和最后一个顶点外, 其余顶点不重复出现的回路称为简单回路
- 路径长度: 路径上边的数目
- 点到点的距离: 从顶点u出发到顶点v的最短路径若存在, 则此路径的长度称为从u到v的距离。若u到v根本不存在路径,则记该距离为无穷(∞)。
- **无向图**中, 若从顶点v到顶点w有路径存在, 则称v和w是**连通**的
- **有向图**中, 若从顶点v到顶点w和从顶点w到顶点v之间都有路径, 则称这两个顶点是**强连通**的
## 连通图
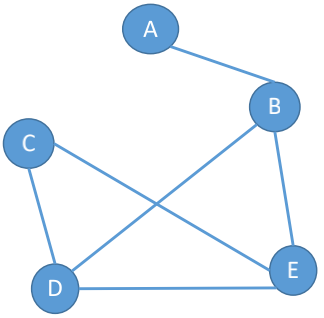
若图G中任意两个顶点都是连通的, 则称图G为**连通图**, 否则称为**非连通图**
对于n个顶点的无向图G
若G是**连通图,** 则最少有n-1条边
若G是**非连通图**, 则最多可能有$C^2_{n-1}$条边
## 强连通图
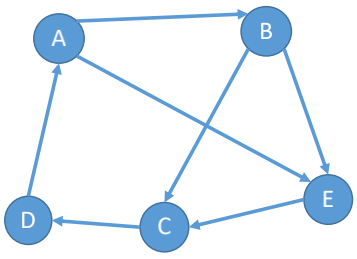
若图中任何一对顶点都是强连通的, 则称此图为**强连通图**
对于n个顶点的有向图G, 若G是强连通图, 则最少有n条边(形成回路)
## 图的局部
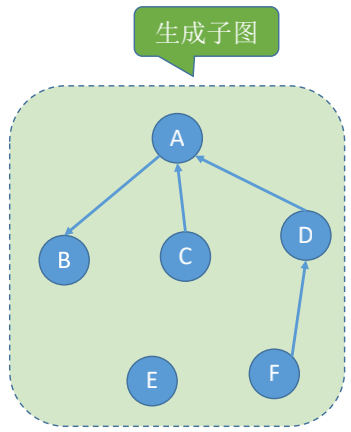
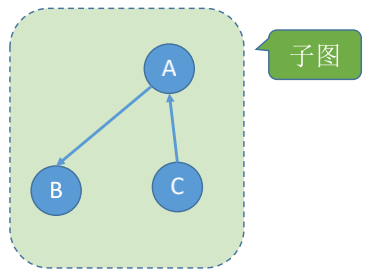
### 子图
设两个图$G=(V,E)$和$G'=(V', E')$, 若$V'$是$V$的子集, 且$E'$是$E$的子集, 则称$G'$是$G$的子图
若有满足$V(G')=V(G)$的子图$G'$, 则称其为$G$的生成子图
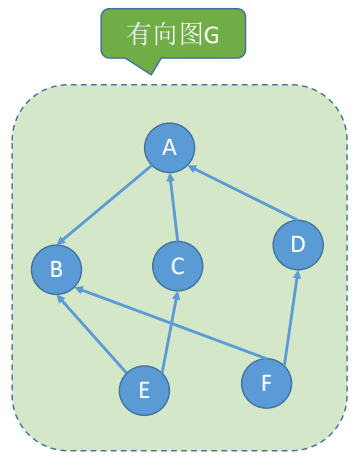
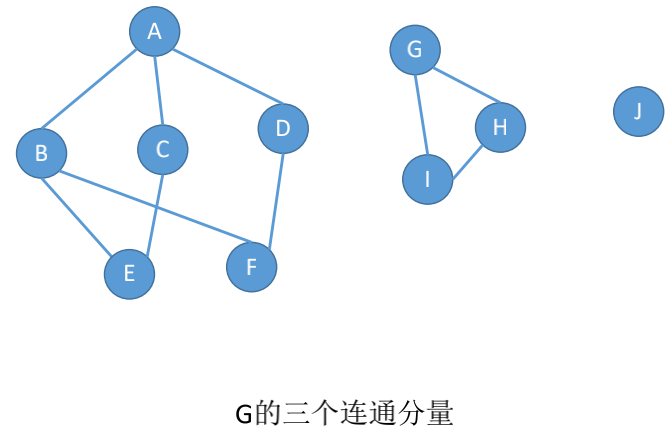
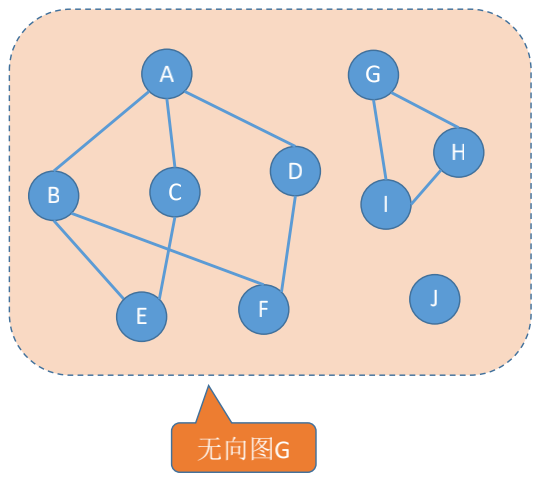
### 连通分量
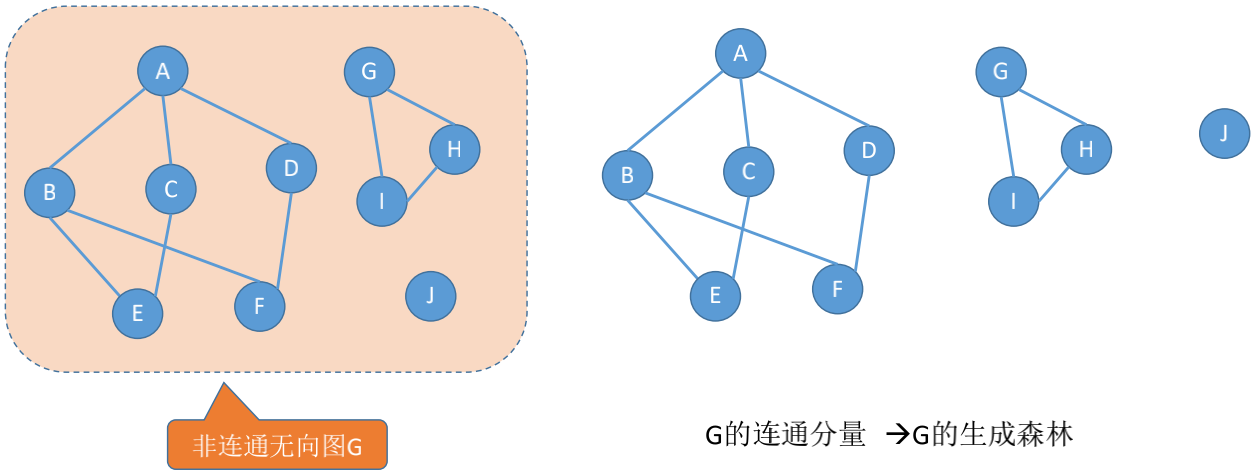
无向图中的极大连通子图称为连通分量。
**极大连通子图**: 子图必须连通, 且包含尽可能多的顶点和边
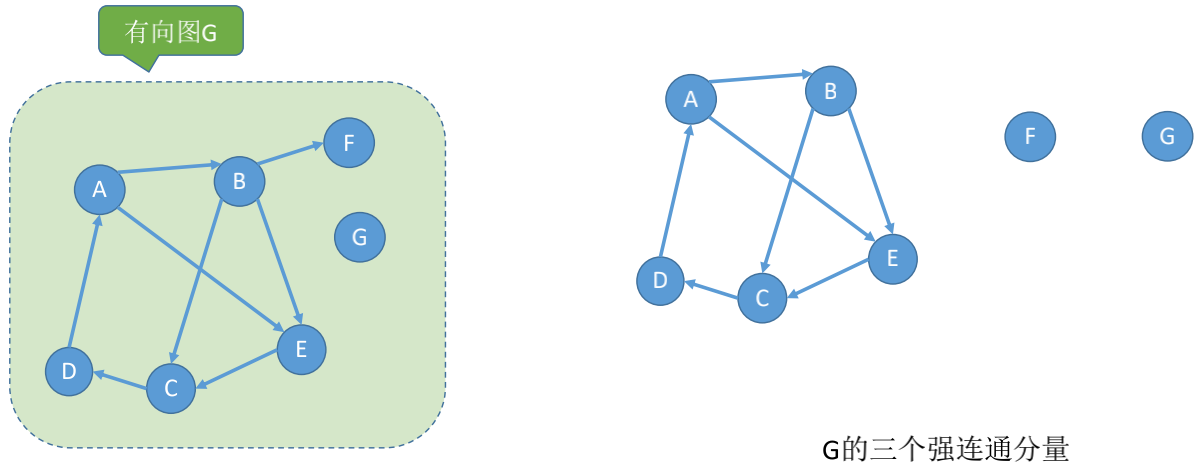
### 强连通分量
有向图中的极大强连通子图称为有向图的强连通分量
**极大强连通子图**: 子图必须强连通, 且保留尽可能多的边
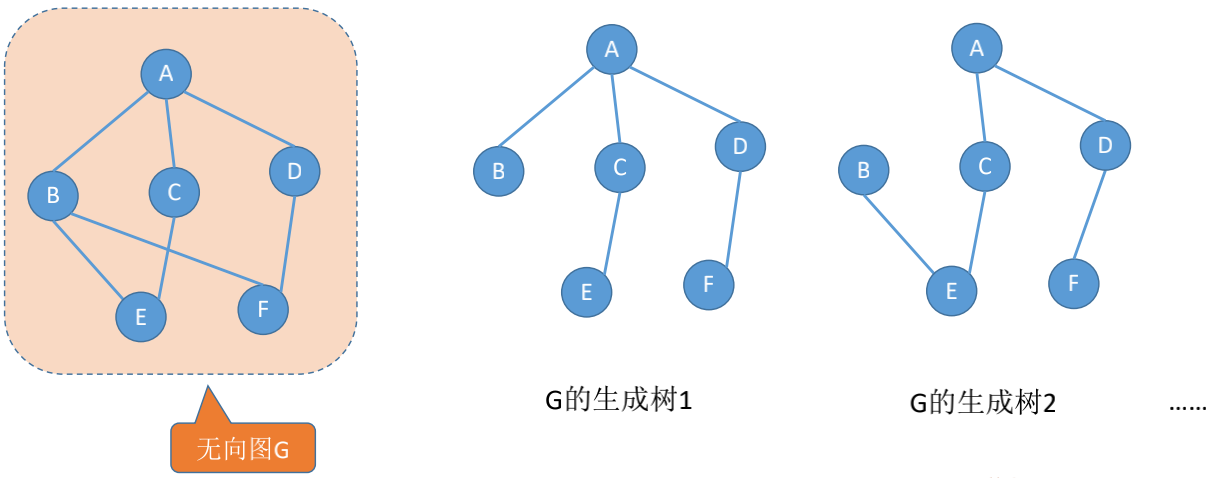
### 生成树
**连通图**的生成树是**包含图中全部顶点的一个极小连通子图(边尽可能的少, 但要保持连通)**
若图中顶点数为n, 则它的生成树含有**n-1**条边。对生成树而言,若砍去它的一条边,则会变成非连通图,若加上一条边则会形成一个回路
### 生成森林
在**非连通图中**, **连通分量的生成树**构成了非连通图的生成森林
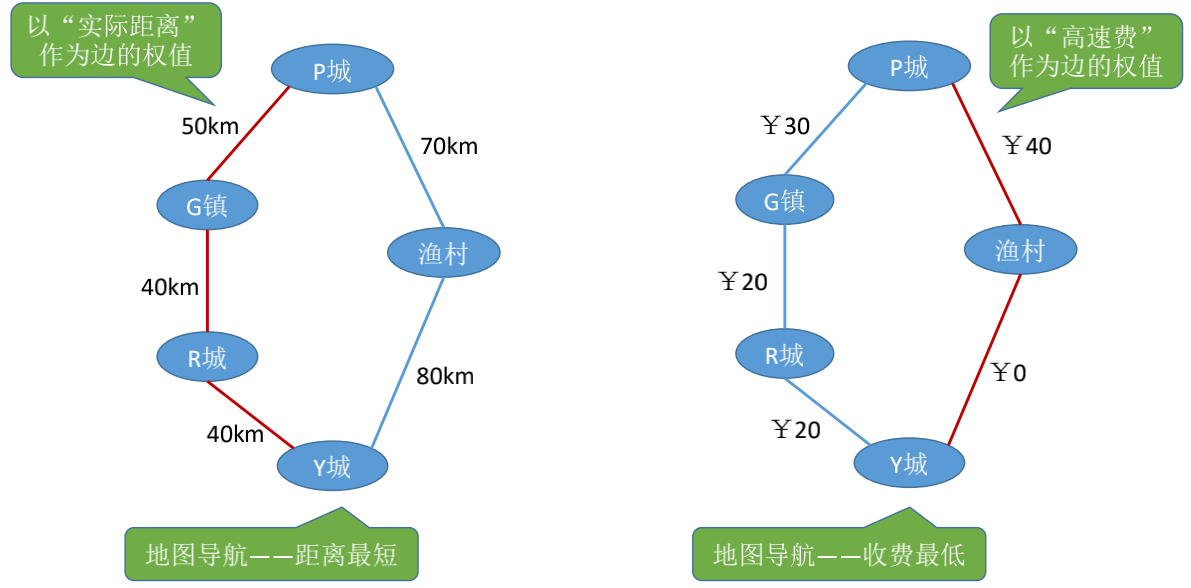
## 边的权、带全图/网
边的权: 在一个图中, 每条边有可以表上具有某种含义的数值, 该数值称为该边的权值
带权图/网: 边上带有权值的图称为带权图, 也称网
带权路径长度: 当图是带权图时, 一条路径上所有边的权值之和, 称为该路径的带权路径长度
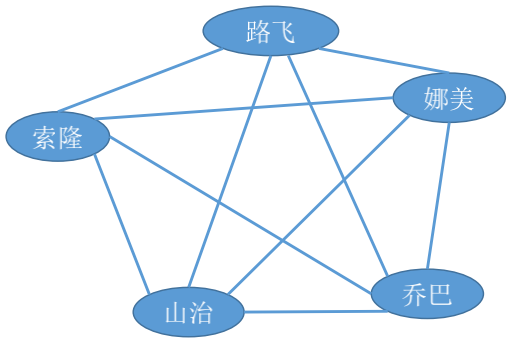
## 特殊形态的图
### 无向完全图
无向完全图: 无向图中任意两个顶点之间都存在边
若无向图的顶点树为$|V|=n$, 则$|E|∈[0,c_n^2]=[0,n(n-1)/2]$
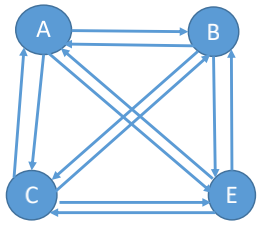
### 有向完全图
有向完全图: 有向图中任意两个顶点之间都存在方向相反的两条弧
若有向图的顶点数$|V|=n$,则$|E|∈[0,2C_n^2]=[0,n(n-1)]$
### 稀疏图
边数很少的图称为稀疏图(没有绝对的界限, 一般来说$|E|<|V|log|V|$)时, 可以将G视为稀疏图
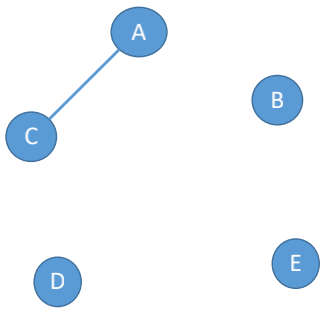
### 稠密图
稀疏图反之对应的是稠密图
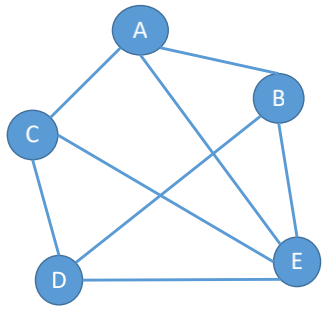
### 树
树: 不存在回路, 且连通的无向图
n个顶点的树, 必有n-1条边 ** =>** n个顶点的图, 若$|E|>n-1$, 则一定有回路
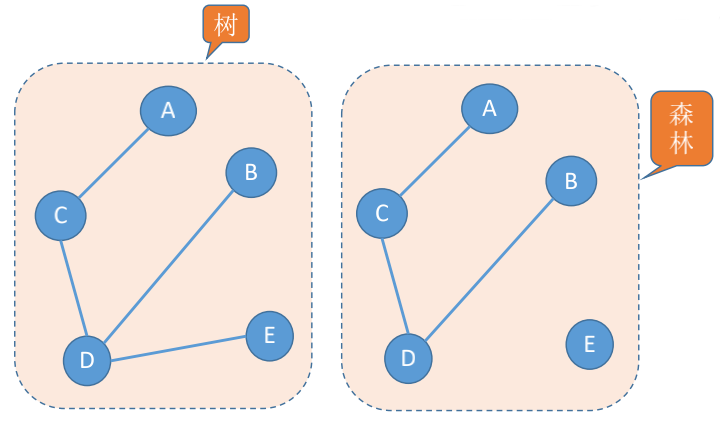
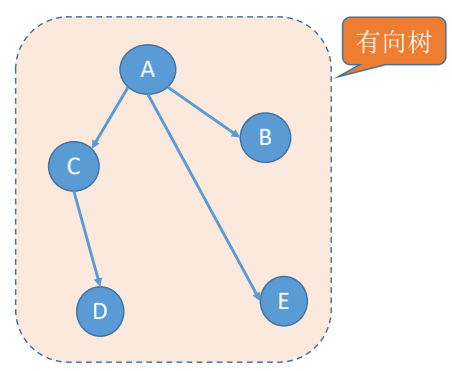
### 有向树
有向树: 一个顶点的入度为0、其余顶点的入度均为1的有向图,称为有向树
## 常见考点
对于n个顶点的无向图G,
- 所有顶点的度之和=2|E|
- 若G是连通图, 则最少有n-1条边(树), 若 |E| > n-1, 则一定有回路
- 若G是非连通图, 则最多可能有$C_{n-1}^2$条边
- 无向完全图共有$C_n^2$条边
对于n个顶点的有向图G,
- 所有顶点的出度之和=入度之和=|E|
- 所有顶点的度之和=2|E|
- 若G是强连通图, 则最少有n条边(形成回路)
- 有向完全图共有$2C_n^2$条边
# 图的存储
| | **邻接矩阵** | **邻接表** | **十字链表** | **邻接多重表** |
| --- | --- | --- | --- | --- |
| **空间复杂度** | O(|V|²) | 无向图O(|V| + 2|E|)
有向图O(|V| + |E|) | O(|V| + |E|) | O(|V| + |E|) |
| **找相邻边** | 遍历对应行或列
时间复杂度为O(|V|) | 找有向图的入边必须遍历整个邻接表 | 很方便 | 很方便 |
| **删除边或顶点** | 删除边很方便, 删除顶点需要大量移动数据 | 无向图中删除边或顶点都不方便 | 很方便 | 很方便 |
| **适用于** | 稠密图 | 稀疏图和其他 | 只能存有向图 | 只能存无向图 |
| **表示方式** | 唯一 | 不唯一 | 不唯一 | 不唯一 |
## 邻接矩阵
结点数为n的图$G=(V,E)$的邻接矩阵A是$n \times n$的. 将G的顶点编号为$v_1,v_2,...,n_n$, 则$$\begin{equation}
\begin{aligned}
A[i][j]=
\begin{cases}
1, & 若(v_i,v_j)或<v_i,v_j>是E(G)中的边\\
0, & 若(v_i,v_j)或<v_i,v_j>不是E(G)中的边
\end{cases}
\end{aligned}
\end{equation}$$
### 性质
设图G的邻接矩阵为$A$(矩阵元素为0/1), 则$A^n$的元素$A^n[i][j]$等于由顶点 i 到顶点 j 的长度为 n 的路径的数目
### 顶点的度、出度、入度
无向图:
- 第i个结点的度=第i行(或第i列)的非零元素个数
有向图:
- 第i个结点的出度 = 第i行的非零元素个数
- 第i个结点的入度 = 第i列的非零元素个数
- 第i个结点的度 = 第i行、第i列的非零元素个数之和
邻接矩阵法求顶点的度、出度、入度的时间复杂度为$O(|V|)$
### 性能
空间复杂度: $O(|V|^2)$ 只和顶点数相关, 和实际边数无关
适合用于存储**稠密图**
无向图的邻接矩阵是对称矩阵, 可以**压缩存储**(只存储上三角区或下三角区)
#### 压缩存储
策略: 只存储主对角线+下三角区。按**行优先**原则将各元素存入一维数组中。
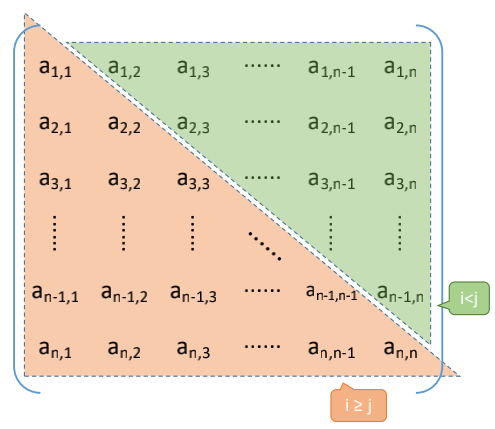
$$ a_{i,j}=a_{j,i} (对称矩阵的性质)$$
$$矩阵下标 => 一维数组下标 \\
a_{i,j} => B[k]$$
$$k=
\begin{cases}
i(i-1)/2+j-1, & i ≥j(下三角区和主对角线元素)\\
j(j-1)/2 + i - 1, & i<j(上三角区元素a_{ij}=a_{ji})
\end{cases}$$
### 代码实现
```java
import lombok.Data;
import java.util.*;
@Data
public class Graph<T extends Comparable<T>> {
/**
* storage vertex
*/
private List<T> vertexList;
/**
* storage adjacency matrix of the graph
*/
private int[][] edges;
/**
* denotes the number of edges
*/
private int numOfEdges;
public Graph(int n) {
edges = new int[n][n];
vertexList = new ArrayList<>(n);
numOfEdges = 0;
}
/**
* add vertex to vertexList
*
* @param vertex vertex of graph
*/
public void insertVertex(T vertex) {
vertexList.add(vertex);
}
/**
* add edge
*
* @param v1 index of first vertex
* @param v2 index of second vertex
* @param weight weight value of vertex
*/
public void insertEdge(int v1, int v2, int weight) {
edges[v1][v2] = weight;
edges[v2][v1] = weight;
numOfEdges++;
}
public void show() {
for (int[] edge : edges) {
System.out.println(Arrays.toString(edge));
}
}
}
```
## 邻接表法
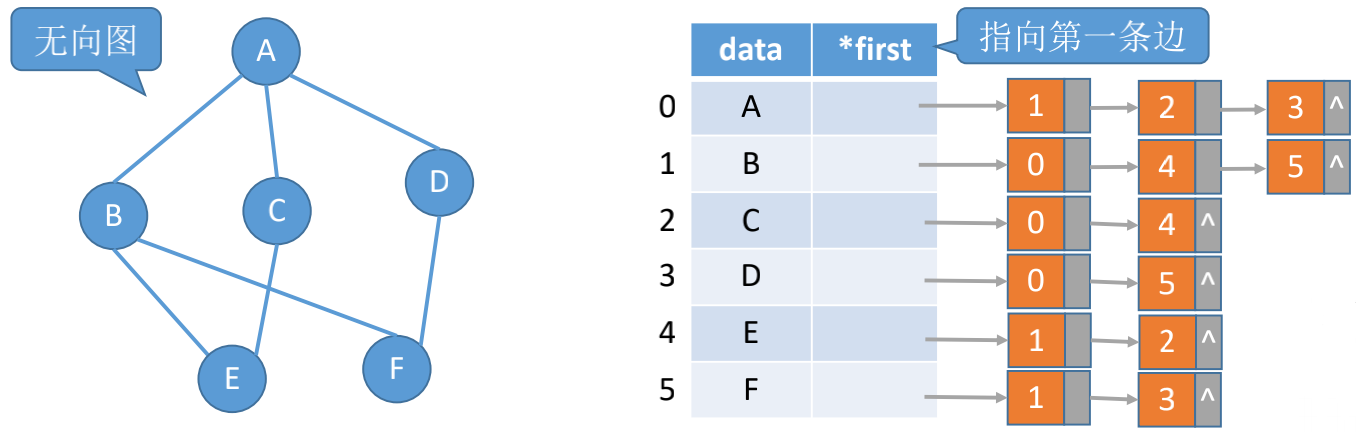
邻接表采用顺序+链式的方式存储
| | **邻接表** | **邻接矩阵** |
| --- | --- | --- |
| **空间复杂度** | 无向图O(|V| + 2 |E|); 有向图O(|V| + |E|) | O(|V| ^ 2) |
| **适合用于** | 存储稀疏图 | 存储稠密图 |
| **表示方式** | 不唯一 | 唯一 |
| **计算度/出度/入度** | 计算有向图的度/入度不方便, 其余方便 | 必须遍历对应行或列 |
| **找相邻的边** | 找到有向图的入边不方便, 其余方便 | 必须遍历对应行或列 |
```java
// 边/弧的结点
class ArcNode {
int adjVen; // 边/弧指向哪个结点
ArcNode next; // 指向下一条弧的指针
}
// 顶点
class VNode<T> {
T data;
ArcNode first;
}
// 邻接表存储的图
class ALGraph<T> {
Vnode<T>[] vertices;
int vexNum;
int arcNum;
}
```
## 十字链表
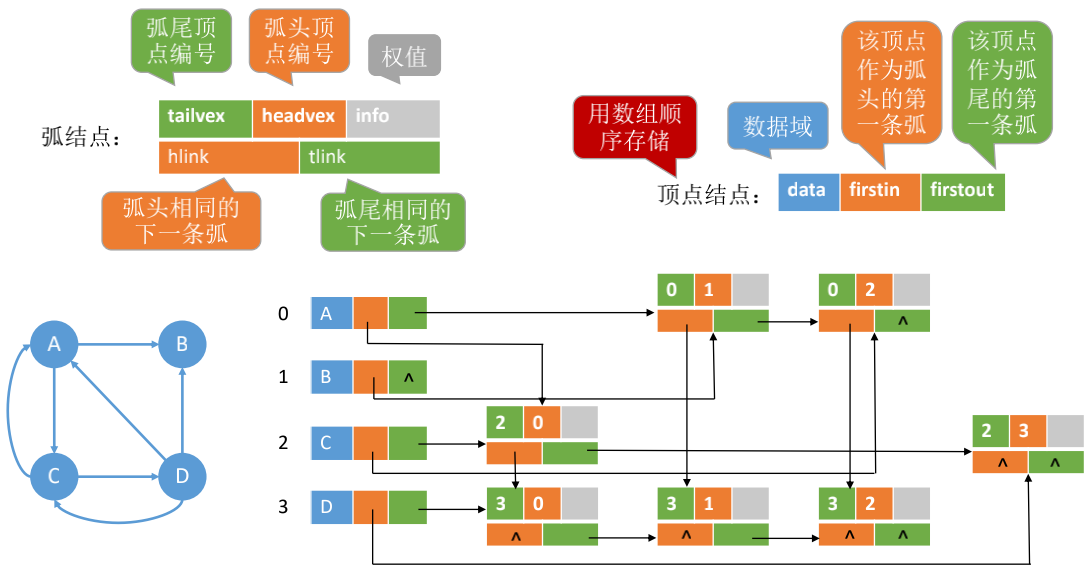
空间复杂度: $O(|V|+|E|)$
如何找到指定顶点的所有**出边**? -- 顺着绿色线路找
如何找到指定顶点的所有**入边**? -- 顺着橙色线路找
十字链表只用于存储有向图
```java
class ArcNode {
// 弧尾顶点编号
int tailVex;
// 弧头顶点编号
int headVex;
// 权值
int info;
// 弧头相同的下一条弧
ArcNode hLink;
// 弧尾相同的下一条弧
ArcNode tlink;
}
class VexNode<T> {
// 数据域
T data;
// 该顶点作为弧头的第一条弧
ArcNode firstIn;
// 该顶点作为弧尾的第一条弧
ArcNode firstOut;
}
```
## 邻接多重表
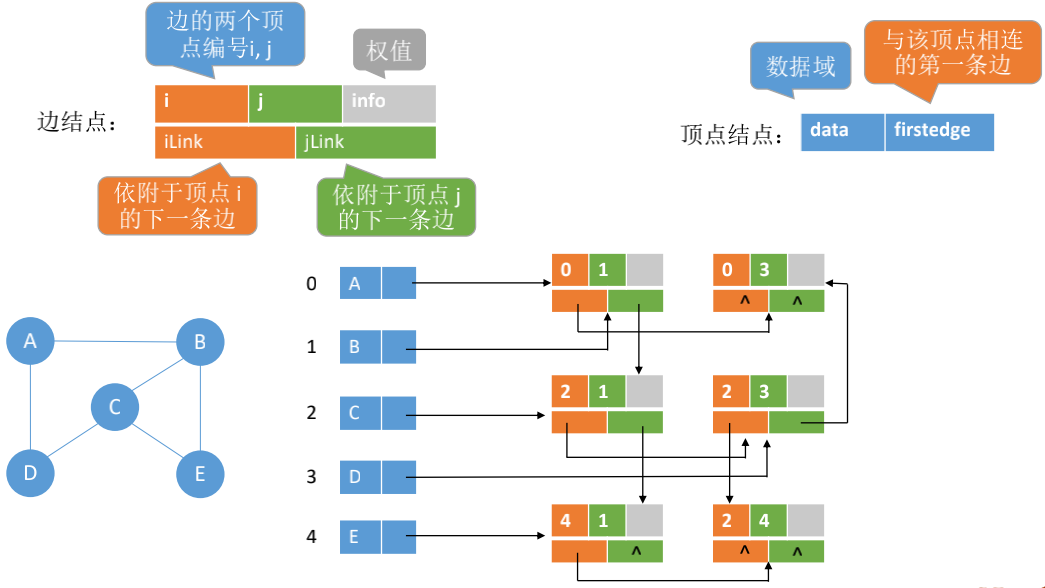
```java
class EdgeNode {
// 边的两个顶点编号i, j
int i, j;
// 权值
int info;
// 依附于顶点i,j的下一条边
EdgeNode iLink, jLink;
}
class VertexNode {
// 数据域
int data;
// 与该顶点相连的第一条边
EdgeNode firstEdge;
}
```
# 图的遍历
## 深度优先遍历(DFS)
深度优先搜索算法(英语:Depth-First-Search,**DFS**)是一种用于遍历或搜索树或图的算法
DFS会尽可能深的搜索树的分支。当节点v的所在边都已被探寻过,搜索将回溯到发现节点v的那条边的起始节点。这个过程一直进行到从源节点可达的所有节点为止。如果还存在未被发现的节点,则选择其中一个源节点并重复以上过程,整个进程反复进行直到所有节点被访问为止。
### 实现方法
1. 首先将根结点放入stack中
1. 从stack中取出第一个节点,并检验它是否为目标
1. 如果找到目标,则结束搜寻并回传结果
1. 否则将它某一个尚未检验的直接子节点加入stack中
3. 重复步骤2
3. 如果不存在未检测的直接子节点
1. 将上一级节点加入stack中
1. 重复步骤2
5. 若stack为空,表示整张图都检查过了
### 代码实现
```java
package com.algorithm.datastruct;
import lombok.Data;
import java.util.*;
@Data
public class Graph<T extends Comparable<T>> {
/**
* storage vertex
*/
private List<T> vertexList;
/**
* storage adjacency matrix of the graph
*/
private int[][] edges;
/**
* denotes the number of edges
*/
private int numOfEdges;
/**
* record whether a node has been accessed
*/
private boolean[] isVisited;
public Graph(int n) {
edges = new int[n][n];
vertexList = new ArrayList<>(n);
numOfEdges = 0;
}
/**
* add vertex to vertexList
*
* @param vertex vertex of graph
*/
public void insertVertex(T vertex) {
vertexList.add(vertex);
}
/**
* add edge
*
* @param v1 index of first vertex
* @param v2 index of second vertex
* @param weight weight value of vertex
*/
public void insertEdge(int v1, int v2, int weight) {
edges[v1][v2] = weight;
edges[v2][v1] = weight;
numOfEdges++;
}
public void show() {
for (int[] edge : edges) {
System.out.println(Arrays.toString(edge));
}
}
public T getValueByIndex(int i) {
return vertexList.get(i);
}
public int getWeight(int v1, int v2) {
return edges[v1][v2];
}
/**
* get the index of first adjacency vertex
*
* @param index index to be found
* @return success return index, failure return -1
*/
public int getFirstNeighbor(int index) {
for (int i = 0; i < vertexList.size(); i++) {
if (edges[index][i] > 0) {
return i;
}
}
return -1;
}
/**
* get the index of next adjacency vertex by the previous adjacency vertex
*
* @param v1 x of previous adjacency vertex
* @param v2 y of previous adjacency vertex
* @return success return index, failure return -1
*/
public int getNextNeighbor(int v1, int v2) {
for (int i = v2 + 1; i < vertexList.size(); i++) {
if (edges[v1][i] > 0) {
return i;
}
}
return -1;
}
public void dfs(boolean[] isVisited, int i) {
System.out.print(getValueByIndex(i) + (i + 1 == vertexList.size() ? "" : "->"));
isVisited[i] = true;
int w = getFirstNeighbor(i);
while (w != -1) {
if (!isVisited[w]) {
dfs(isVisited, w);
}
w = getNextNeighbor(i, w);
}
}
public void dfs() {
isVisited = new boolean[vertexList.size()];
for (int i = 0; i < vertexList.size(); i++) {
if (!isVisited[i]) {
dfs(isVisited, i);
}
}
}
}
```
## 广度优先遍历(BFS)
广度优先搜索算法(英语:Breadth-First Search,缩写为**BFS**),又译作宽度优先搜索,或横向优先搜索,是一种图形搜索演算法。
BFS是从根节点开始,沿着树的宽度遍历树的节点。如果所有节点均被访问,则算法中止。广度优先搜索的实现一般采用open-closed表。
### 实现方法
1. 首先将根结点放入队列中
1. 从队列中取出第一个节点, 并检验它是否为目标
1. 如果找到目标, 则结束搜寻并回传结果
1. 否则将它所有尚未检验过的直接子节点加入队列中
3. 若队列为空, 表示整张图都检查过了 -- 即图中没有欲搜寻的目标. 结束搜寻并返回null。
3. 重复步骤2
### 代码实现
```java
public void bfs(boolean[] isVisited, int i) {
Queue<Integer> queue = new ArrayDeque<>();
System.out.print(getValueByIndex(i) + (i + 1 == vertexList.size() ? "" : "=>"));
isVisited[i] = true;
queue.add(i);
// index of queue head node
int u;
// adjacency vertex
int w;
while (!queue.isEmpty()) {
u = queue.poll();
w = getFirstNeighbor(u);
while (w != -1) {
if (!isVisited[w]) {
System.out.print(getValueByIndex(w) + (w + 1 == vertexList.size() ? "" : "=>"));
isVisited[w] = true;
queue.add(w);
}
w = getNextNeighbor(u, w);
}
}
}
public void bfs() {
isVisited = new boolean[vertexList.size()];
for (int i = 0; i < vertexList.size(); i++) {
if (!isVisited[i]) {
bfs(isVisited, i);
}
}
}
```
# 最小生成树(MST)
## 最小生成树的概念
**最小生成树**是一副连通加权无向图中一颗权值最小的生成树
对于一个**带权连通无向图**$G=(V,E)$, 生成树不同, 每棵树的权(即树种所有边上的权值之和)也可能不同. 设R为G的所有生成树的集合, 若T为R中边的权值之和最小的生成树, 则T称为G的最小生成树(Minimum-Spanning-Tree, **MST**)
- 最小生成树可能有多个, 但边的权值之和总是唯一且最小的
- 最小生成树的边数 = 顶点数 - 1。砍掉一条则不连通,增加一条边则会出现回路
- 如果一个连通图本身就是一颗树,则其最小生成树就是它本身
- 只有连通图才有生成树,非连通图只有生成森林
## Prim算法
**普里姆算法**(Prim's algorithm), 于1930年由捷克数学家沃伊捷赫·亚尔尼克发现;并在1957年由美国计算机科学家罗伯特·普里姆独立发现;1959年,艾兹格·迪科斯彻再次发现了该算法
**算法描述: **从某一顶点开始构建生成树; 每次将代价(权值)最小的新顶点纳入生成树, 直到所有顶点都纳入为止
**时间复杂度**: $O(|V|^2)$
适合用于边**稠密图**
[Prim算法可视化(即时实现)](https://www.cs.usfca.edu/~galles/visualization/Prim.html)****
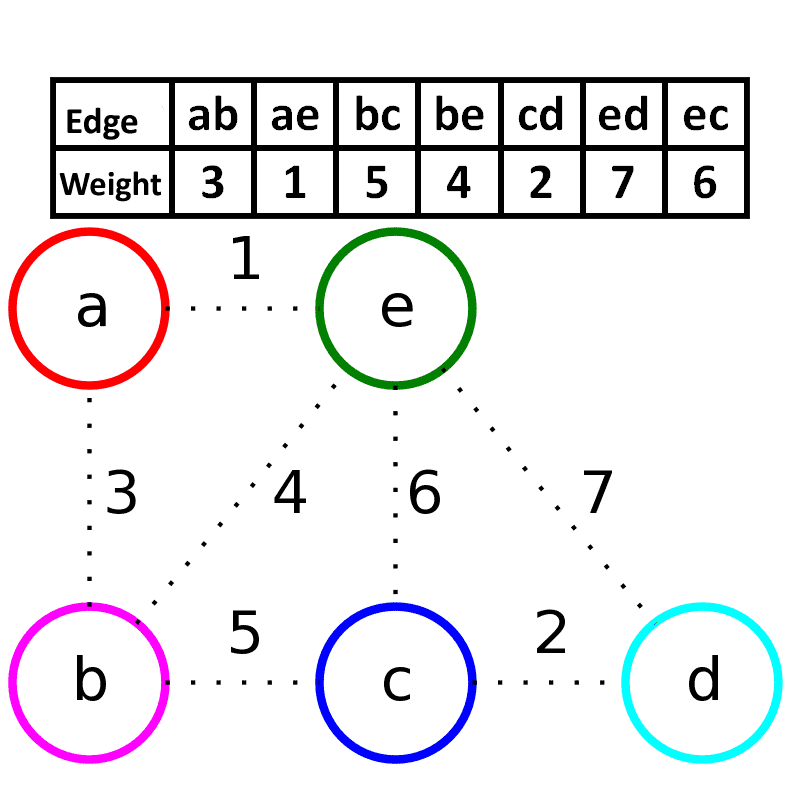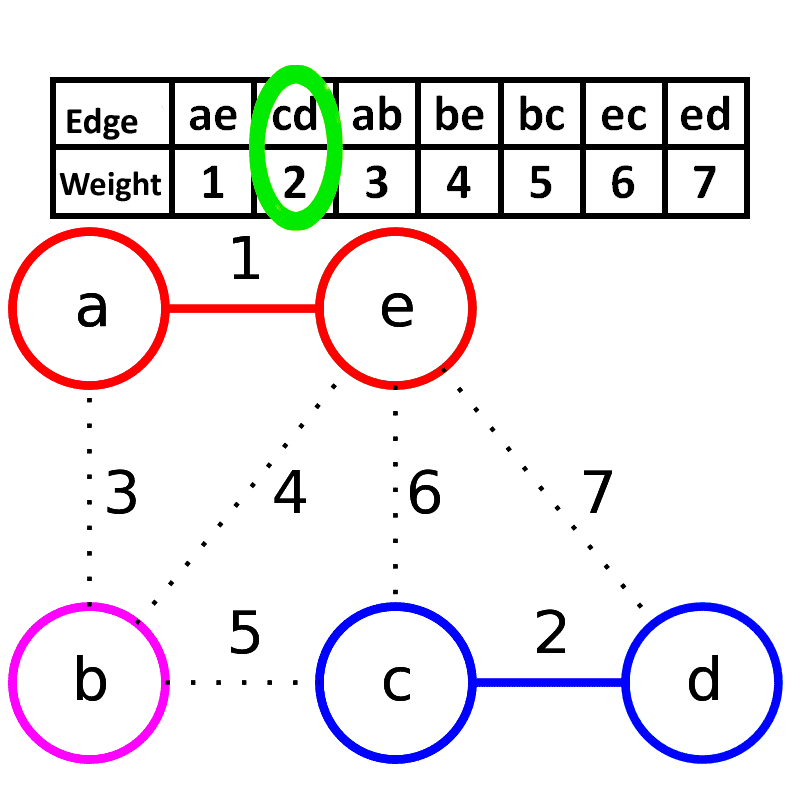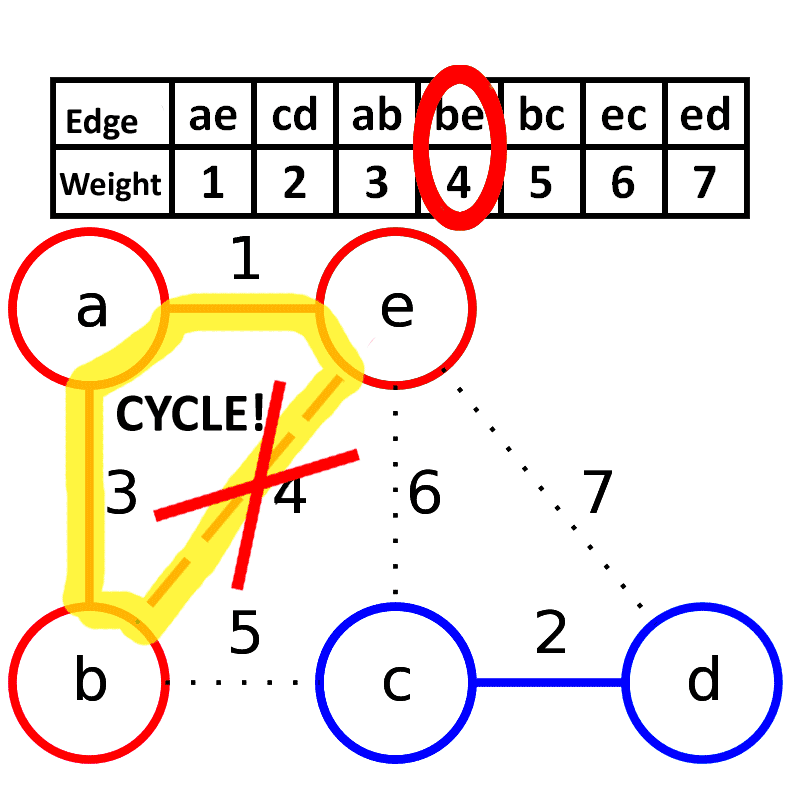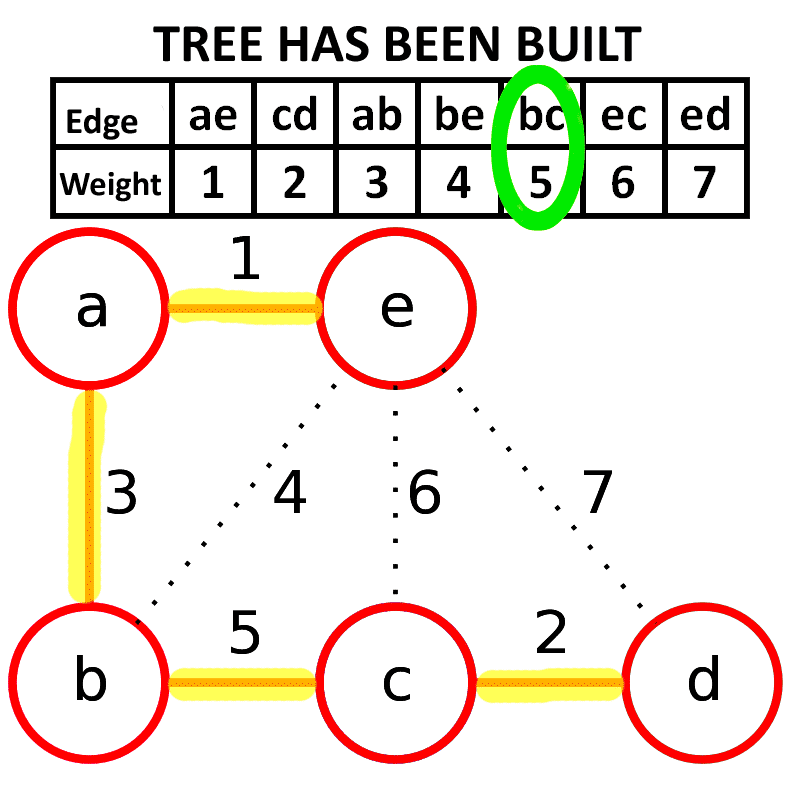
## Kruskal算法
Kruskal算法是一种用来查找最小生成树的算法, 由Joseph Kruskal在1956年发表
**算法描述**: 每次选择一条权值最小的边, 使这条边的两头连通(原来已经连通的就不选), 直到所有结点都连通
**时间复杂度**: $O(|E|log_2|E|)$
适合用于边**稀疏图**
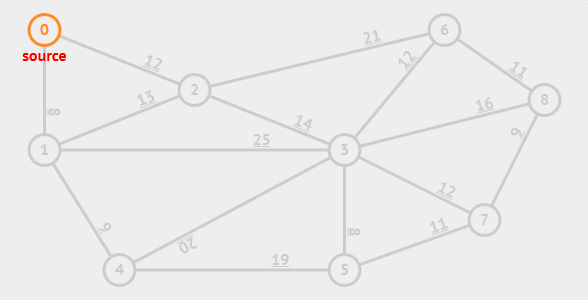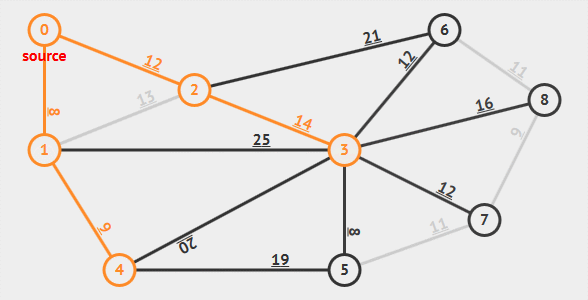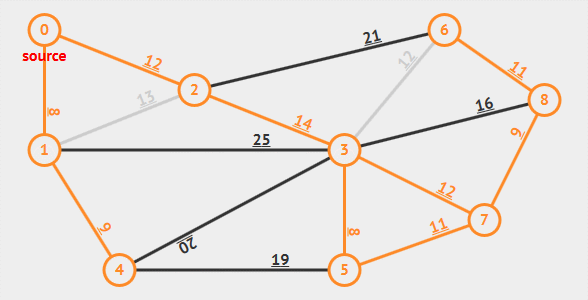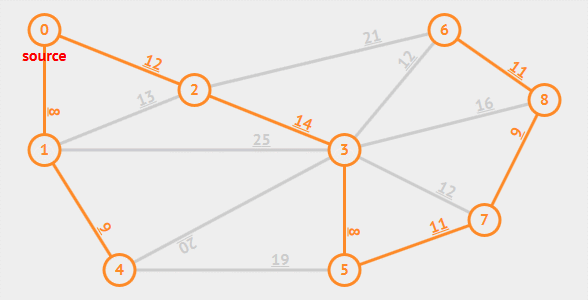
# 最短路径问题
## BFS算法
## Dijkstra算法
Dijkstra(/ˈdikstrɑ/或/ˈdɛikstrɑ/)算法由荷兰计算机科学家 E. W. Dijkstra 于 1956 年发现,1959 年公开发表。是一种求解 **非负权图** 上单源最短路径的算法。
### 流程
将结点分为两个集合:已确定最短路长度的点集(记为$S$集合)和未确定最短路长度的点集(记为$T$集合)。一开始所有的点都属于$T$集合。
初始化$dis(s) = 0$,其他的$dis$均为$+∞$。
然后重复这些操作:
1. 从$T$集合中,选取一个最短路长度最小的结点,移到$S$集合中。
1. 对那些刚刚被加入$S$集合的结点的所有出边执行松弛操作。
直到T集合为空,算法结束。
### 时间复杂度
- 暴力:$O(n^2 + m) = O(n^2)$
- 二叉堆:$O((n+m)logn)=O(mlogn)$
- 优先队列:$O(mlogm)$
- Fibonacci堆:$O(nlogn+m)=O(nlogn)$
- 线段树:$O(mlogn)$
### 代码实现
## Floyd算法
# 有向无环图描述表达式
# 拓扑排序
# 关键路径